Явные внешние ключи
| Преимущества | |
| Нужно только два столбца | Условия соединения - явные |
| Недостатки | |
| Оба дополнительных атрибута должны использоваться в соединениях | Слишком много столбцов |
Альтернативные модели сущностей:
Вариант 1 (плохой)

Вариант 2 (существенно лучше, если подтипы действительно существуют)

Вариант 3 (годится при наличии осмысленного супертипа D).

Язык модулей
Структура модуля SQL в стандарте SQL/89 определяется следующими синтаксическими правилами:
<module> ::= <module name clause> <language clause> <module autorization clause> [<declare cursor>...] < procedure > ... <module name clause> ::= MODULE [<module name>] <language clause> ::= LANGUAGE { COBOL FORTRAN PASCAL PLI } <module autorization clause> ::= AUTHORIZATION <module autorization identifier> <module autorization identifier> ::= <autorization identifier>
Существенно, что каждый модуль SQL ориентирован на использование в программах, написанных на конкретном языке программирования. Если в модуле присутствуют процедуры работы с курсорами, то все курсоры должны быть специфицированы в начале модуля. Заметим, что объявление курсора не погружается в какую-либо процедуру, поскольку это описательный, а не выполняемый оператор SQL.
Язык модулей или встроенный SQL?
В стандарте SQL/89 определены два способа взаимодействия с БД из прикладной программы, написанной на традиционном языке программирования (как мы уже упоминали, SQL/89 ориентирован на использование совместно с языками Кобол, Фортран, Паскаль и ПЛ/1, но в реализациях обычно поддерживается и язык Си).
Язык программирования Java
Весь 1996 год прошел под знаком внедрения в World Wide Web технологии Java. Однако реальные проекты, выполненные в этой технологии появились только к концу года. При обсуждении Java-технологии, как правило речь идет о ее безопасности, мобильности, и, как следствие, уменьшении размеров программного кода, выполняемого на машинах-клиентах.
Не смотря на то, что этот раздел называется "Язык программирования Java", в нем приходится говорить о гораздо более обширном понятии, которое принято обозначать термином "Java-технология". Если обратиться к публикациям о новых концепциях разработки программного обеспечения, то Java-язык и Java-технологии ценятся не только и не столько за то, что они дали возможность "оживить" Web, как часто можно прочитать в рекламных проспектах, а за то, что давняя идея мобильного программирования для различных аппаратных платформ наконец-то стала реальностью.
При этом все прекрасно понимают, что сама по себе Java-технология еще чрезвычайно сыра и использовать ее в нынешнем виде для серьезных проектов могут только самые отчаянные смельчаки, тем не менее многие из свойств Java чрезвычайно интересны и полезны.
Язык SQL - базовый интерфейс SQL-сервера
Одним из основных преимуществ реляционного подхода к организации баз данных (БД) является то, что пользователи реляционных БД получают возможность эффективной работы в терминах простых и наглядных понятий таблиц, их строк и столбцов без потребности знания реальной организации данных во внешней памяти.
Реляционная модель данных, содержащая набор четких предписаний к базовой организации любой реляционной системы управления базами данных (СУБД), позволяет пользователям работать в ненавигационной манере, т.е. для выборки информации из БД человек должен всего лишь указать список интересующих его таблиц и те условия, которым должны удовлетворять выбираемые данные. СУБД скрывает от пользователя выполняемые ей последовательные просмотры таблиц, выполняя их наиболее эффективным образом. Очень важная особенность реляционных систем состоит в том, что результатом выполнения любого запроса к таблицам БД является также таблица, которую можно сохранить в БД и/или по отношению к которой можно выполнять новые запросы.
Базовым требованием к реляционным СУБД является наличие мощного и в тоже время простого языка, позволяющего выполнять все необходимые пользователям операции. В последние годы таким повсеместно принятым языком стал язык реляционных БД SQL - Structured Query Language (теперь все чаще название языка понимается как Standard Query Language).
До появления SQL в СУБД (независимо от того, на какой модели они основывались) приходилось поддерживать по крайней мере три языка, которые обычно имели мало общего: язык определения данных (ЯОД), служащий для спецификации структур БД (обычно общую структуру БД называют схемой БД); язык манипулирования данными (ЯМД), позволяющий создавать прикладные программы, взаимодействующие с БД; и язык администрирования БД (ЯАДБ), с помощью которого можно было выполнять служебные действия (например, изменять структуру БД или производить ее настройку с целью повышения эффективности). Кроме того, если требовалось предоставить пользователям СУБД интерактивный доступ к БД, приходилось вводить еще один язык, операторы которого выполняются в диалоговом режиме. Язык SQL позволяет решать все эти задачи.
Языки БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Sсhema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured или Standard Query Language). В нескольких разделах этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в то смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Языки и протоколы
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы, разработав: язык гипертекстовой разметки документов HTML (HyperText Markup Language), универсальный способ адресации ресурсов в сети URL (Universal Resource Locator), протокол обмена гипертекстовой информацией HTTP (HyperText Transfer Protocol). Позже команда NCSA (National Center of Supercomputer Applications) добавила к этим трем компонентам четвертый - универсальный интерфейс шлюзов CGI (Common Gateway Interface). Усовершенствования на этом не остановились. В 1995 году Netscape Communication предлагает включить в текст HTML-страниц программы на новом языке Liveware. Позже это название было изменено на JavaScript. Таким образом технология World Wide Web была дополнена еще одним компонентом - языком программирования просмотра гипертекстовых страниц JavaScript.
Исходя из важности технологии WWW для построения корпоративных Intranet-систем, мы для начала коротко рассмотрим два базовых компонента этой технологии - язык гипертекстовой разметки документов HTML и протокол обмена гипертекстовой информацией HTTP.
Классический подход к проектированию реляционных баз данных
При проектировании базы данных решаются две основных проблемы:
Каким образом отобразить объекты предметной области в абстрактные объекты модели данных, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.)? Часто эту проблему называют проблемой логического проектирования баз данных. Как обеспечить эффективность выполнения запросов к базе данных, т.е. каким образом, имея в виду особенности конкретной СУБД, расположить данные во внешней памяти, создание каких дополнительных структур (например, индексов) потребовать и т.д.? Эту проблему называют проблемой физического проектирования баз данных.
В случае реляционных баз данных трудно представить какие-либо общие рецепты по части физического проектирования. Здесь слишком много зависит от используемой СУБД. Например, при работе с СУБД Ingres можно выбирать один из предлагаемых способов физической организации отношений, при работе с System R следовало бы прежде всего подумать о кластеризации отношений и требуемом наборе индексов и т.д. Поэтому в этом разделе мы ограничимся вопросами логического проектирования реляционных баз данных, которые существенны при использовании любой реляционной СУБД.
Более того, мы не будем касаться очень важного аспекта проектирования - определения ограничений целостности (за исключением ограничения первичного ключа). Дело в том, что при использовании СУБД с развитыми механизмами ограничений целостности (например, SQL-ориентированных систем) трудно предложить какой-либо общий подход к определению ограничений целостности. Эти ограничения могут иметь очень общий вид, и их формулировка пока относится скорее к области искусства, чем инженерного мастерства. Самое большее, что предлагается по этому поводу в литературе, это автоматическая проверка непротиворечивости набора ограничений целостности.
Так что будем считать, что классическая проблема проектирования реляционной базы данных состоит в обоснованном принятии решений о том, из каких отношений должна состоять БД и какие атрибуты должны быть у этих отношений.
Клиент-серверные приложения
Под клиент-серверным приложением мы будем понимать информационную систему, основанную на использовании серверов баз данных (см. длинное замечание в конце раздела 2.1). Общее представление информационной системы в архитектуре "клиент-сервер" показано на рисунке 2.3.
На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции (пока нас не будет занимать, как строится код приложения). Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения.
(Здесь опять проявляются недостатки в терминологии. Обычно, когда компания объявляет о выпуске очередного сервера баз данных, то неявно понимается, что имеется и клиентская составляющая этого продукта. Сочетание "клиентская часть сервера баз данных" кажется несколько странным, но нам придется пользоваться именно этим термином.)

Рис. 2.3. Общее представление информационной системы в архитектуре "клиент-сервер"
Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения.
Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Здесь необходимо сделать еще два замечания.
Обычно компании, производящие развитые серверы баз данных, стремятся к тому, чтобы обеспечить возможность использования своих продуктов не только в стандартных на сегодняшний день TCP/IP-ориентированных сетях, но в сетях, основанных на других протоколах (например, SNA или IPX/SPX).
Поэтому при организации сетевых взаимодействий между клиентской и серверной частями СУБД часто используются не стандартные средства высокого уровня (например, механизмы программных гнезд или вызовов удаленных процедур), а собственные функционально подобные средства, менее зависящие от особенностей сетевых транспортных протоколов. Когда мы говорим об интерфейсе на основе языка SQL, нужно отдавать себе отчет в том, что несмотря на титанические усилия по стандартизации этого языка, нет такой реализации, в которой стандартные средства языка не были бы расширены. Необдуманное использование расширений языка приводит к полной зависимости приложения от конкретного производителя сервера баз данных.
Мы остановимся на этих вопросах более подробно в четвертой части курса.
Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL.
Сервер производит компиляцию полученного оператора. Не будем здесь останавливаться на том, какой целевой язык используется конкретным компилятором; в разных реализациях применяются различные подходы (примеры см. в части 4). Главное, что в любом случае на основе информации, содержащейся в таблицах-каталогах базы данных производится преобразование непроцедурного представления оператора в некоторую процедуру его выполнения. Далее (если компиляция завершилась успешно) происходит выполнение оператора. Мы снова не будем обсуждать технические детали, поскольку они различаются в реализациях. Рассмотрим возможные действия операторов SQL.
Оператор может относиться к классу операторов определения (или создания) объектов базы данных (точнее и правильнее было бы говорить про элементы схемы базы данных или про объекты метабазы данных). В частности, могут определяться домены, таблицы, ограничения целостности, триггеры, привилегии пользователей, хранимые процедуры. В любом случае, при выполнении оператора создания элемента схемы базы данных соответствующая информация помещается в таблицы-каталоги базы данных (в таблицы метабазы данных).
Ограничения целостности обычно сохраняются в метабазе данных прямо в текстовом представлении. Для действий, определенных в триггерах, и хранимых процедур вырабатывается и сохраняется в таблицах-каталогах процедурный выполняемый код. Заметим, что ограничения целостности, триггеры и хранимые процедуры являются, в некотором смысле, представителями приложения в поддерживаемой сервером базе данных; они составляют основу серверной части приложения (см. ниже). При выполнении операторов выборки данных на основе содержимого затрагиваемых запросом таблиц и, возможно, с использованием поддерживаемых в базе данных индексов формируется результирующий набор данных (мы намеренно не используем здесь термин "результирующая таблица", поскольку в зависимости от конкретного вида оператора результат может быть упорядоченным, а таблицы, т.е. отношения неупорядочены по определению). Серверная часть СУБД пересылает результат клиентской части, и окончательная обработка производится уже в клиентской части приложения. При выполнении операторов модификации содержимого базы данных (INSERT, UPDATE, DELETE) проверяется, что не будут нарушены определенные к этому моменту ограничения целостности (те, которые относятся к классу немедленно проверяемых), после чего выполняется соответствующее действие (сопровождаемое модификацией всех соответствующих индексов и журнализацией изменений). Далее сервер проверяет, не затрагивает ли данное изменение условие срабатывания какого-либо триггера, и если такой триггер обнаруживается, выполняет процедуру его действия. Эта процедура может включать дополнительные операторы модификации базы данных, которые могут вызвать срабатывание других триггеров и т.д. Можно считать, что те действия, которые выполняются на сервере баз данных при проверке удовлетворенности ограничений целостности и при срабатывании триггеров, представляют собой действия серверной части приложения. При выполнении операторов модификации схемы базы данных (добавления или удаления столбцов существующих таблиц, изменения типа данных существующего столбца существующей таблицы и т.д.) также могут срабатывать триггеры, т.е., другими словами, может выполняться серверная часть приложения. Аналогично, триггеры могут срабатывать при уничтожении объектов схемы базы данных (доменов, таблиц, ограничений целостности и т.д.). Особый класс операторов языка SQL составляют операторы вызова ранее определенных и сохраненных в базе данных хранимых процедур.
Если хранимая процедура определяется с помощью достаточно развитого языка, включающего и непроцедурные операторы SQL, и чисто процедурные конструкции (например, языка PL/SQL компании Oracle), то в такую процедуру можно поместить серьезную часть приложения, которое при выполнении оператора вызова процедуры будет выполняться на стороне сервера, а не на стороне клиента. При выполнении оператора завершения транзакции сервер должен проверить соблюдение всех, так называемых, отложенных ограничений целостности (к таким ограничениям относятся ограничения, накладываемые на содержимое таблицы базы целиком или на несколько таблиц одновременно; например, суммарная зарплата сотрудников отдела 999 не должна превышать 150 млн. руб.). Снова к проверке отложенных ограничений целостности можно относиться как к выполнению серверной части приложения.
Как видно, в клиент-серверной организации клиенты могут являться достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов (рисунок 2.4).
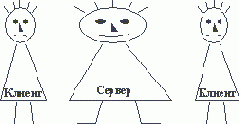
Рис. 2.4. "Тонкий" клиент и "толстый" сервер в клиент-серверной архитектуре
С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента.
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных (или, как иногда их называют в русскоязычной литературе, тиражированных) баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных - упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа.
Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения - от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. В любом случае, клиенты становятся более толстыми при том, что сервер тоньше не делается (рисунок 2.5).

Рис. 2.5. "Потолстевший" клиент и "толстый" сервер в клиент-серверной архитектуре с поддержкой локального кэша на стороне клиентов
Сформулируем некоторые предварительные выводы. Архитектура "клиент-сервер" на первый взгляд кажется гораздо более дорогой, чем архитектура "файл-сервер". Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления базами данных. Однако, это верно лишь частично. Громадным преимуществом клиент-серверной архитектуры является ее масштабируемость и вообще способность к развитию.
При проектировании информационной системы, основанной на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике.
Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. В идеале, которого, конечно же не бывает, информационная система продолжает нормально функционировать после смены аппаратуры.
Компания IBM
Решение компании IBM называется A Data Warehouse Plus. Целью компании является обеспечение интегрированного набора программных продуктов и сервисов, основанных на единой архитектуре. Основой складов данных является семейство СУБД DB2. Преимуществом IBM является то, что данные, которые нужно извлечь из оперативной базы данных и поместить в склад данных, находятся в системах IBM. Поэтому естественная тесная интеграция программных продуктов.
Предлагаются три решения для складов данных:
Изолированный рынок данных. Предназначен для решения отдельных задач вне связи с общим хранилищем корпорации. Зависимый рынок данных. Аналогичен изолированному рынку данных, но источники данных находятся под централизованным контролем. Глобальный склад данных. Корпоративное хранилище данных, которое полностью централизовано контролируется и управляется. Глобальный склад данных может храниться централизовано или состоять из нескольких распределенных в сети рынков данных.
Концептуальные модели и схемы баз данных
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного нами механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс.
При этом проявляется ограниченность реляционной модели данных в следующих аспектах:
Модель не предоставляет достаточных средств для представления смысла данных. Семантика реальной предметной области должна независимым от модели способом представляться в голове проектировщика. В частности, это относится к упоминавшейся нами проблеме представления ограничений целостности. Для многих приложений трудно моделировать предметную область на основе плоских таблиц. В ряде случаев на самой начальной стадии проектирования проектировщику приходится производить насилие над собой, чтобы описать предметную область в виде одной (возможно, даже ненормализованной) таблицы. Хотя весь процесс проектирования происходит на основе учета зависимостей, реляционная модель не предоставляет каких-либо средств для представления этих зависимостей. Несмотря на то, что процесс проектирования начинается с выделения некоторых существенных для приложения объектов предметной области ("сущностей") и выявления связей между этими сущностями, реляционная модель данных не предлагает какого-либо аппарата для разделения сущностей и связей.
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. При том, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Прежде, чем мы коротко рассмотрим особенности одной из распространенных семантических моделей, остановимся на их возможных применениях.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную. При этом известны два подхода: на основе явного представления концептуальной схемы как исходной информации для компилятора и построения интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области. И в том, и в другом случае в результате производится реляционная схема базы данных в третьей нормальной форме (более точно следовало бы сказать, что автору неизвестны системы, обеспечивающие более высокий уровень нормализации).
Наконец, третья возможность, которая еще не вышла (или только выходит) за пределы исследовательских и экспериментальных проектов, - это работа с базой данных в семантической модели, т.е. СУБД, основанные на семантических моделях данных. При этом снова рассматриваются два варианта: обеспечение пользовательского интерфейса на основе семантической модели данных с автоматическим отображением конструкций в реляционную модель данных (это задача примерно такого же уровня сложности, как автоматическая компиляция концептуальной схемы базы данных в реляционную схему) и прямая реализация СУБД, основанная на какой-либо семантической модели данных. Наиболее близко ко второму подходу находятся современные объектно-ориентированные СУБД, модели данных которых по многим параметрам близки к семантическим моделям (хотя в некоторых аспектах они более мощны, а в некоторых - более слабы).
Линия серверных продуктов CA-OpenIngres компании Computer Associates
Проект и экспериментальный вариант СУБД Ingres были разработаны в университете Беркли под руководством одного из наиболее известных в мире ученых и специалистов в области баз данных Майкла Стоунбрейкера (Michael Stonebraker). С самого начала СУБД Ingres разрабатывалась как мобильная система, функционирующая в среде ОС UNIX. Первая версия Ingres была рассчитана на 16-разрядные компьютеры и работала главным образом на машинах серии PDP. Это была первая СУБД, распространяемая бесплатно для использования в университетах. Впоследствии группа Стоунбрейкера перенесла Ingres в среду ОС UNIX BSD, которая также была разработана в университете Беркли. Семейство СУБД Ingres из университета Беркли принято называть "университетской Ingres" (соответствующие программные продукты вместе с исходными текстами и документацией до сих пор доступны в секторе public domain Internet).
В начале 80-х была образована компания RTI (Relational Technology Inc.) для доводки университетских прототипов до уровня коммерческих продуктов. С этого момента стали различать университетскую и коммерческую СУБД Ingres. В настоящее время коммерческая Ingres поддерживается, развивается и продается компанией Computer Associates. Сейчас это одна из развитых коммерческих реляционных СУБД.
Мы коснемся, главным образом, особенностей базового серверного продукта компании Computer Associates линии CA-OpenIngres - CA-OpenIngres/Server. Сервер базируется на следующих пяти ключевых архитектурных принципах компании Computer Associates:
использование многопоточной и мультипроцессорной организации сервера для систем оперативной обработки транзакций (OLTP - On-Line Transaction Processing); применение более развитых методов обработки данных для систем уровня OLAP (On-Line Analitical Processing); безопасное и надежное управление данными информационных приложений; обеспечение расширенных инструментальных средств администрирования серверной части системы (это вообще конек компании; у них больше всего внимания обращается на администрирование и управление систем); возможность гибкой настройки сервера в соответствии с конкретными потребностями корпорации.
Архитектура CA- OpenIngres Server поддерживает совместное использование многочисленных серверов баз данных на основе поддержки совместного буферного кэша, в котором хранятся данные, объекты, откомпилированные запросы, хранимые процедуры и информация, характеризующая состояние транзакций. Средства администрирования и управления позволяют выделить некоторые серверы для целей оперативного управления транзакциями, в то время как другие будут использоваться для генерации отчетов с более низким приоритетом.
В соответствии с начальным подходом Стоунбрейкера, в сервере поддерживается широкий набор допустимых способов хранения данных: куча (heap), B-деревья, таблицы хэширования и т.д. Допускается поддержание индексов с избыточными столбцами данных для эффективного выполнения особо критичных запросов. Применяются способы сжатия таблиц и индексов.
При оптимизации запросов учитываются разнообразные допустимые формы хранения. Используются истинные распределения данных за счет динамического построения гистограмм распределений значений. Для особо критических запросов поддерживаются административные способы оптимизации.
В соответствии с традициями Ingres в CA-OpenIngres поддерживается встроенная система правил (расширенный вариант более или менее известного механизма триггеров). Расширенные языковые возможности определения правил позволяют решать на основе этого механизма не только задачи поддержания целостности баз данных, но и полностью разрешать производственные задачи.
В CA-OpenIngres поддерживаются стандарты SQL-89 и ядерный уровень языка SQL-92. (Обратите внимание, что никто из ведущих производителей не гарантирует полной совместимости с SQL-92. Это очень плохо, поскольку уже на протяжении более чем 4 лет, ни одна компания не может или не хочет произвести продукт, полностью соответствующий требованиям хорошего международного стандарта. Правда, и стандарт несколько сложноват.)
Очень интересным направлением развития линии CA-OpenIngres явилось приобретение японской объектно-ориентированной СУБД Jasmin.
Это оригинальная объектно- ориентированная система, модель данных которой основывается одновременно на идеях Smalltalk и Си++. Компания Computer Associates считает, что в принципе невозможно сочетать в одной системе объектно-ориентированный и реляционный подходы (в частности, отметим по-прежнему существующую проблему потери соответствия объектных и реляционных операций [impedance mismatch], присущую объектно-реляционным системам).
Поэтому в ближайших планах компании содержатся намерения одновременного поддержания объектно-ориентированного и реляционного интерфейсов доступа к базам данных, среда хранения которых будет поддерживаться OpenIngres. Сама же СУБД OpenIngres поддерживает возможности шлюзования для доступа к унаследованным системам баз данных (в частности, IDMS), что обеспечивает полную преемственность по отношению к ранее разработанным и накопленным хранилищам данных. К сожалению, в текстах, распространяемых компанией CA, содержится слишком мало технической информации относительно Jasmin. Однако достоверно известно, что объектно-ориентированные возможности управления данными широко используются в новом продукте компании, предназначенном для управления и администрирования глобально распределенных корпоративных приложений и называемом TNG (The Next Generation of UniCenter).
Login
.
Ниже приведена структура корня FTP-архива (рисунок 5.5).

Рис. 5.5. Структура ftp-архива
Many-to-many
). Поэтому часто ограничения общего вида не выводятся автоматически из концептуальной схемы базы данных и их приходится добавлять к реляционной схеме вручную. Для того, чтобы понять, какие ограничения общего вида должны быть включены в реляционные схемы разделов, приходится возвращаться к документу, содержащему анализ требований корпорации. Задача проектировщика состоит в том, чтобы, с одной стороны, выявить все необходимые ограничения целостности и, с другой стороны, не перегрузить базу данных необязательными ограничениями (любое дополнительное ограничение целостности вызывает дополнительные проверки на стороне сервера при выполнении операций изменения базы данных; проверки для ограничений общего вида могут быть весьма громоздкими). Конечно, если предполагается использование распределенной базы данных, то опять придется учитывать возможности сервера по части ссылок на объекты "чужих" разделов. Это может повлиять на выбор ограничений целостности и/или повлечь создание новой декомпозиции общей базы данных на разделы.
Триггер - это, фактически, хранимая процедура без параметров, содержащая оператор(ы) изменения базы данных и вызываемая сервером баз данных автоматически при совершении некоторого события (обычно под событием понимается выполнение определенного рода операторов изменения базы данных). Более точно, при определении триггера указывается вид события, возбуждающего триггер, условие его срабатывания и набор операторов, которые должны быть выполнены при выполнении условия. Имеется несколько практических областей применения механизма триггеров. Во-первых, триггеры позволяют поддерживать логическую целостность базы данных в тех случаях, когда пользовательская транзакция не может не нарушить эту целостность. Простой пример: информационная система отдела кадров. База данных состоит из двух таблиц:
СОТРУДНИКИ(НОМЕР_ПРОПУСКА, ФИО, НОМЕР_ОТДЕЛА, ЗАРПЛАТА)
ОТДЕЛЫ (НОМЕР_ОТДЕЛА, НОМЕР_ПРОПУСКА_НАЧАЛЬНИКА, ЧИСЛО_СОТРУДНИКОВ, ФОНД_ЗАРПЛАТЫ)
Естественные ограничения целостности могут быть выражены следующим образом:
SELECT ЧИСЛО_СОТРУДНИКОВ FROM ОТДЕЛЫ = SELECT COUNT (*) FROM СОТРУДНИКИ WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
SELECT ФОНД_ЗАРПЛАТЫ FROM ОТДЕЛЫ <= SELECT SUM (ЗАРПЛАТА) FROM СОТРУДНИКИ WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
Предположим, что в отделе кадров работает всего два человека: начальник отдела кадров, который, естественно, имеет доступ к обеим таблицам и, в частности, является ответственным за выполнение операций смены начальника отдела или изменения фонда заработной платы. Второй человек - рядовой клерк, который по указанию начальника выполняет рутинную работу оформления новых сотрудников или увольнения ранее работавших. Естественно, что для выполнения его операций достаточно иметь доступ только к таблице СОТРУДНИКИ. Но тогда при выполнении любой из двух операций он просто не может не нарушить, по крайней мере, первое из упомянутых выше ограничений целостности. Конечно, можно внести соответствующие корректирующие действия в код прикладной программы, соответствующей операциям клерка, но тогда он неявно получит доступ по изменению ответственной таблицы ОТДЕЛЫ. Поэтому лучше определить триггеры вида
ON INSERT TO СОТРУДНИКИ UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) + 1 WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
ON DELETE FROM СОТРУДНИКИ UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) - 1 WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
Эти триггеры будут автоматически вызываться на стороне сервера баз данных и незаметно для клерка поддерживать логическую целостность базы данных. Вторая область применения триггеров - автоматический мониторинг действий конечных пользователей. Снова приведем очень простой пример. Начальник отдела кадров хочет знать, сколько операций в день выполняет его клерк. Тогда он должен сказать об этом на стадии анализа требований, и в результате, например, будет создана таблица
СТАТИСТИКА (ТЕКУЩАЯ_ДАТА, ЧИСЛО_ОПЕРАЦИЙ)
и триггер вида
ON INSERT, DELETE FROM СОТРУДНИКИ IF EXISTS (SELECT * FROM СТАТИСТИКА WHERE ТЕКУЩАЯ_ДАТА = TODAY) UPDATE СТАТИСТИКА SET NEW (ЧИСЛО_ОПЕРАЦИЙ) = OLD (ЧИСЛО_ОПЕРАЦИЙ) + 1 WHERE ТЕКУЩАЯ_ДАТА = TODAY ELSE INSERT INTO СТАТИСТИКА (TODAY, 1)
Два замечания. Во-первых, в распространенном на сегодня стандарте SQL-92 механизм триггеров не специфицирован. В СУБД, которые поддерживают этот механизм, соответствующие языковые средства и их семантика различаются. Например, в Oracle V.7 для определения триггеров можно использовать процедурное расширение языка SQL PL/SQL в то время, как другие системы позволяют использовать только "чистые" конструкции SQL. Поэтому на текущий момент использование механизма триггеров неявно влечет сильную привязку к конкретному производителю. Во-вторых, как и в случае определения представлений и ограничений целостности, при определении триггеров необходимо учитывать распределенный характер базы данных и возможности сервера ссылаться на "чужие" таблицы.
Наконец, в базе данных могут храниться хранимые процедуры. Интересно, что в стандарте SQL-92 вообще не встречается термин "хранимая процедура". В стандарте специфицированы два способа взаимодействия прикладной программы с сервером баз данных. Первый, наиболее часто используемый способ состоит в встраивании операторов языка SQL в программу, написанную на одном из традиционных языков программирования. В самом стандарте определены правила встраивания SQL в программы, которые написаны на языках Си, Паскаль, Фортран, Ада и т.д. Второй способ основан на специфицированном в стандарте "языке модулей SQL". С использованием этого языка можно определить модуль, содержащий несколько процедур, каждая из которых соответствует некоторому параметризованному оператору SQL. В прикладной программе содержатся не операторы SQL, а лишь вызовы процедур (с указанием фактических параметров) из модуля SQL, с которым эта прикладная программа связана (правила связывания в стандарте не определены). Заметим, что стандарт не обязывает следовать каким-то конкретным правилам при реализации встроенного SQL или языка модулей. Посмотрим, что же делается в реализациях.
Что касается встроенного SQL, то во всех реализациях прикладная программа, содержащая операторы SQL, подвергается прекомпиляции с помощью соответствующего программного продукта, который входит в состав программного обеспечения сервера баз данных.
В результате прекомпиляции всегда формируется текст прикладной программы на используемом языке программирования, уже не содержащий напрямую текста на языке SQL. Каждое вхождение оператора SQL в исходный текст программы заменяется на вызов некоторой процедуры или функции в синтаксисе включающего языка программирования. Основная разница между разными реализациями состоит в том, что из себя представляет эта процедура или функция. В большинстве систем (Oracle, Informix, Sybase, CA-OpenIngres) такая процедура представляет собой обращение к клиентской части СУБД с передачей в качестве параметра текста оператора на языке SQL. Вся обработка оператора, включая его грамматический разбор и выработку процедурного плана производится сервером во время выполнения прикладной программы (конечно, при повторном выполнении оператора сервер использует уже подготовленный план). Однако имеется и другой подход, исторически используемый компанией IBM в ее серии продуктов DB2. В DB2 прекомпилятор, выбрав текст очередного оператора SQL, сам обращается к серверу с запросом на компиляцию оператора. Сервер выполняет грамматический разбор и строит процедурный план выполнения оператора, сохраняя этот план в базе данных и привязывая к соответствующей прикладной программе. В качестве ответа от сервера прекомпилятор получает идентификатор, указание которого серверу повлечет выполнение соответствующего плана (грубо говоря, имя удаленной процедуры). Тогда в тексте прикладной программы появится вызов процедуры-переходника (stub), которая жестко привязана к соответствующей удаленной процедуре. Другими словами, более распространен метод динамической компиляции встроенного SQL (при выполнении прикладной программы), но имеются примеры реализаций со статической компиляцией встроенных операторов SQL (при прекомпиляции текста прикладной программы со встроенным SQL) (таблица 1.1.). В этом курсе мы не будем рассматривать сравнительные преимущества и недостатки динамического и статического подходов.
Таблица 1.1.Характеристики динамической и статической схем обработки встроенного SQL
и позволяет построить модель данных,Метод IDEF1, разработанный Т.Рэмей (T.Ramey), также основан на подходе П.Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. В настоящее время на основе совершенствования методологии IDEF1 создана ее новая версия - методология IDEF1X. IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEF1X-диаграммы используются рядом распространенных CASE-средств (в частности, ERwin, Design/IDEF). Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рисунок 4.13).  Рис. 4.13. Сущности Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком. Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей: каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка; каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка; каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка; каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка. Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае - неидентифицирующей. Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Мощность связи обозначается как показано на рисунке 4.14 (мощность по умолчанию - N).  Рис.4.14. Мощность связи Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией (рисунок 4.15). Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).  Рис. 4.15. Идентифицирующая связь Пунктирная линия изображает неидентифицирующую связь (рисунок 4.16). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.  Рис. 4.16. Неидентифицирующая связь Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рисунок 4.17).  Рис. 4.17. Атрибуты и первичные ключи Сущности могут иметь также внешние ключи (Foreign Key), которые могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рисунок 4.18).  Рис. 4.18. Примеры внешних ключей Методы доступаВ настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD. Миграция от средства программированияЛомая копья вокруг предназначения и места Java в Internet вообще и в Web в частности, полезно обратить внимание на историю развития технологии. А история Java поучительна. Самое интересное ее изложение приведено в эпилоге книги Патрика Нотона "Java. Справочное руководство", одного из руководителей "Зеленого проекта" Sun, одним из результатов которого собственно и стал Java. С самого начала никакого Java не было. Был Oak (Дуб), да и весь проект никакого отношения к сетям вообще и к Internet в частности не имел. Собственно речь шла о технологии программирования электронных устройств широкого потребления. Одним из ключевых моментов этой технологии являлся язык программирования интерфейсов. Предполагалось, что все бытовые приборы (но не только они) будут иметь панель управления некоторым универсальным устройством, которое и будет уже управлять всем прибором в целом. Для программирования этого устройства, а точнее его панели управления и предназначался Oak. Из затеи создать устройство управления приборами ничего не вышло: уж больно дорогим оно получалось. Применить данную технологию к интерактивному телевидению также не удалось. В итоге, Нотон осознал, что устройство собственно уже есть - это персональный компьютер, который может управлять сразу всеми приборами, а его операционной системой является продукция Microsoft. Однако, в это время уже появились Web и Netscape. Развлечения ради написали свой собственный браузер на Oak, который в последствии получил название HotJava. Браузер умел делать то, что не умели другие программы этого класса - интерпретировать мобильные коды нового языка. При этом в качестве демонстрации возможностей использовался смешной человечек "Дюк", который махал рукой и прыгал по экрану. Вот когда это все заработало, тогда собственно и появилась Java. Но к этому моменту, реально, до уровня стандартных инструментов были проработаны только элементы интерфейса пользователя, все остальное развивалось в рамках HotJava, а это не самый удачный браузер сети. Поэтому сейчас язык Java добирает то, в чем ему было отказано при рождении - возможность работать с сетью. Но это только полбеды. Другим серьезным препятствием на пути новой технологии является отсутствие средств разработки прикладных программ для взаимодействия с СУБД. И здесь активность разработчиков этих средств просто поражает. Практически все производители СУБД лицензировали Java и начали разработку продуктов этого класса. К сожалению, пока о каких-либо стандартных решениях здесь говорить не приходится, хотя и есть определенные сдвиги. MIME(Multipurpose Internet Mail Exchange) - формат почтового сообщения Internet. В данном контексте стандарт MIME используется для установления соответствия между типом информационного файла, именем этого файла и программой просмотра этого файла. Мобильность JavaПервым из свойств языка Java разберем мобильность. Суть мобильности заключается в том, что написанный на Java код может исполняться на любой компьютерной платформе. Под платформой в данном случае подразумевается программно-аппаратный комплекс, а проще собственно компьютер и операционная система, которая на нем работает. Однако, мобильность Java следует отличать от простого портирования кода с одной платформы на другую. При портировании передается исходный текст, который после этого компилируется и только затем выполняется. В Java передаются так называемые байт-коды. Байт-код - это универсальный формат программы, единый для всех аппаратных платформ. Байт-код един и для рабочих станций, и для больших универсальных ЭВМ, и для персональных компьютеров. Собственно, большинство из тех, кто работал с СУБД на персональных компьютерах с разновидностями байт-кодов наверняка встречался. Это, например, коды, которые выполняет FoxBASE. Конечно коды FoxBASE и Java - это абсолютно разные коды, но идея в общем - та же. Надо сказать, что коды Java - это не единственные мобильные коды, которые предполагалось использовать в Internet, но благодаря большим усилиям со стороны Sun Microsystems именно они стали наиболее известными и, на сегодняшний день используемыми, хотя до сих пор подходят на эту роль слабо. Сравнение с FoxBase было не случайным. Дело в том, что байт-код Java исполняется интерпретатором, а не является откомпилированной на данной платформе программой. Многие преимущества и недостатки Java проистекают именно из-за этого. Первый и очевидный недостаток - это скорость выполнения кода. Совершенно очевидно, что интерпретатор работает гораздо медленнее откомпилированного кода. И здесь не помогут никакие Java-процессоры. Вся элементная база все равно остается двоичной, а это значит, что программы оптимизированные для работы с этим типом вычислений будут работать все равно быстрее, чем какие-либо другие коды. Здесь можно говорить, только о сравнении Java-процессоров с универсальными процессорами при выполнении Java-кода. Собственно, и другие свойства технологии ( объектная ориентируемость, использование многопоточности, отсутствие адресной арифметики и т.п.) в большинстве случаев при стандартной комплектации оборудования, только тормозят выполнение программы. Второй недостаток не столь очевиден, да и собственно для большинства современных разработчиков таковым не является - объектный подход к программированию. Что собственно имеется в виду, когда об объектном программировании говорится как о недостатке в данном контексте. Главным в Java-технологии являются небольшие программки-апплеты, которые передаются по сети. Размер такого апплета очень мал (до сотни строк текста). При этом разработчик должен весь вывод собрать в одну процедуру, перехват особых ситуаций в другую, порождение потоков в третью, и т. д. При этом некоторые из этих процедур будут вообще состоять из четырех - пяти строк. Это конечно дисциплинирует и ведет к построению стройных кодов, но при этом прокрутка текста на экране превращается в программу с порождением нового потока, что вместо сокращения издержек на ее выполнение приводит только к их увеличению. Одним словом, "Hello Java" также нудно писать, как и "Hello Windows". Однако, мобильность Java имеет еще одно измерение. Апплеты передаются по сети в тот момент, когда их нужно выполнять. При этом они могут загружаться из разных мест и после загрузки взаимодействовать друг с другом. Девиз Sun "Сеть - это компьютер" здесь работает на все сто процентов. Действительно, если всю совокупность апплетов рассматривать как одну программу, состоящую из множества подгружаемых по мере необходимости модулей, то весь Internet становится одним большим компьютером, а точнее хранилищем данных и программ, т.к. все-таки программа выполняется на локальном процессоре. Хотя, и последнее не совсем точно. Java-апплеты могут обмениваться данными между собой по сети, что заставляет говорить о распределенных вычислениях, и в этом случае программа будет исполняться на многих компьютерах в сети. До Java можно было говорить о распределенных вычислениях только после трансляции кодов для каждой из машин и отладки всего комплекса в целом. Теперь отладиться можно и на локальном компьютере, а реально считать на разных. Основной протокол обмена апплетами - HTTP. Это значит, что они передаются по сети точно также, как и другие ресурсы Website, и приобретают свое особое значение только в момент получения их браузером. Учитывая неэффективность реализации HTTP поверх TCP, можно сказать, что и обмен апплетами тоже неэффективен, если для каждого обмена устанавливается свое TCP-соединение. Пока сравнение скорости выполнения Java-апплетов и скриптов JavaScript не в пользу первых, т.е. интерпретация скриптов в Netscape Navigator реализована эффективнее. В любом случае загрузка страниц с Java происходит гораздо медленнее, чем без Java. Часто можно слышать, что использование Java должно снизить затраты на обмен информацией по сети. Аргумент здесь следующий: для отображения информации в виде графиков и гистограмм, и даже трехмерных объектов не надо передавать по сети изображения этих объектов, а можно передать, только числовые характеристики. Это приводит к существенному сокращению трафика, и сокращению числа ошибок при передаче. Это справедливо в том случае, если апплеты Java не перегружаются часто. Пользователь загрузил группу страниц и все апплеты на них и только стартует или останавливает выполнение программ. В случае специализированных корпоративных вычислений может быть это и так, но если брать обычного пользователя, то он практически всегда, переходя на новую страницу, загружает новые апплеты, а вот это уже не сокращает трафик, а только увеличивает. Мобильность имеет и свою обратную сторону. Некоторые авторы прежде, чем пустить пользователя на свои страницы с Java предупреждают: Are your going to be infected? Суть предупреждения в том, что, фактически, пользователь разрешает выполняться на своем компьютере программе, о свойствах которой он ничего не знает. При этом ссылки на безопасность Java не вполне корректны.Программа может вообще никак себя внешне не проявлять, но при этом выполнять массу нежелательных, с точки зрения пользователей, действий. Например, анализировать кэш браузера, идентифицировать компьютер пользователя и многое другое. Набор операторов манипулирования даннымиВ стандарте SQL/89 определен очень ограниченный набор операторов манипулирования данными. Их можно классифицировать на группы операторов, связанных с курсором; одиночных операторов манипулирования данными; и операторов завершения транзакции. Все эти операторы можно использовать как в модулях SQL, так и во встроенном SQL. Заметим, что в SQL/89 не определен набор операторов интерактивного SQL. Назначение
Все эти элементы имеют довольно большое количество атрибутов, которые далеко не все реализованы в большинстве интерфейсов. Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т. п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как, например, Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип "text/html". Назначение и разновидности CASE-системВ разряд CASE-средств попадают как относительно дешевые системы для персо-нальных компьютеров с весьма ограни-ченными возможностями, так и дорогостоящие системы для неоднородных вычислительных платформ и опера-ционных сред. Так, современный рынок программных средств насчи-тывает около 300 различных CASE-средств, наиболее мощные из которых так или иначе используются практически всеми ведущими западными фирмами. Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла программного обеспечения и обладающее следующими основными характерными особенностями: мощные графические средства для описания и документирования информационных систем, обеспечивающие удобный интерфейс с разработчиком и развивающие его творческие возможности; интеграция отдельных компонент CASE-средств, обеспечивающая управляемость процессом разработки информационных систем; использование специальным образом организованного хранилища проектных метаданных (репозитория). Интегрированное CASE-средство (или комплекс средств, поддерживающих полный жизненный цикл программного обеспечения) содержит следующие компоненты; репозиторий, являющийся основой CASE-средства. Он должен обеспечивать хранение версий проекта и его отдельных компонентов, синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту и непротиворечивость; графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм (DFD, ER-диаграмма и др.), образующих модели информационных систем; средства разработки приложений, включая языки 4GL и генераторы кодов; средства конфигурационного управления; средства документирования; средства тестирования; средства управления проектом; средства реинжиниринга. Все современные CASE-средства могут быть классифицированы в основном по типам и категориям. Классификация по типам отражает функциональную ориентацию CASE-средств на те или иные процессы жизненного цикла.
Одной из проблем реализации языкаОдной из проблем реализации языка SQL всегда являлась проблема распознавания "изменяемости" соединений. Как известно, если представление включает соединение общего вида, то теоретически невозможно определить, можно ли однозначно интерпретировать операции обновления такого представления. Однако существует несколько важных классов соединений, которые заведомо являются изменяемыми. В SQL-3 предполагается выделить эти классы с помощью специальных синтаксических конструкций. Наконец-то появляется возможность определения триггеров как комбинации спецификаций события и действия. Действие определяется как SQL-процедура, в которой могут использоваться как операторы SQL, так и ряд управляющих конструкций. На самом деле, этот механизм очень близок к тому, который реализован в Oracle V.7. Что касается управления транзакциями, то происходит возврат к старой идее System R о возможности установки внутри транзакции точек сохранения (savepoints). В операторе ROLLBACK можно указать идентификатор ранее установленной точки сохранения, и тогда будет произведен откат транзакции не к ее началу, а к этой точке сохранения. Как видно, можно ожидать наличия в SQL-3 многих интересных и полезных возможностей. Однако даже промежуточные проекты стандарта включают почти в два раза больше страниц, чем стандарт SQL/92. Поэтому трудно ожидать быстрой реализации этого стандарта после его принятия (а многие вообще сомневаются, что этот стандарт будет когда-либо реализован). Назад | Содержание | Вперед Необязательной связи(рисунок 4.20) могут участвовать не все экземпляры сущности.
 Рис. 4.20. Необязательная связь В отличие от необязательной связи в Неперемещаемые (non-transferable) связи:экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 4.12).
 Рис. 4.11. Рекурсивная связь
 Рис. 4.12. Неперемещаемая связь Непосредственное управление данными во внешней памятиЭта функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях серверов баз данных активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД. Нормальная форма Бойса-КоддаРассмотрим следующий пример схемы отношения: СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, СОТР_ИМЯ, ПРО_НОМЕР, СОТР_ЗАДАН) Возможные ключи: СОТР_НОМЕР, ПРО_НОМЕР СОТР_ИМЯ, ПРО_НОМЕР Функциональные зависимости: СОТР_НОМЕР --> CОТР_ИМЯ СОТР_НОМЕР --> ПРО_НОМЕР СОТР_ИМЯ --> CОТР_НОМЕР СОТР_ИМЯ --> ПРО_НОМЕР СОТР_НОМЕР, ПРО_НОМЕР --> CОТР_ЗАДАН СОТР_ИМЯ, ПРО_НОМЕР --> CОТР_ЗАДАН В этом примере мы предполагаем, что личность сотрудника полностью определяется как его номером, так и именем (это снова не очень жизненное предположение, но достаточное для примера). В соответствии с определением 7~ отношение СОТРУДНИКИ-ПРОЕКТЫ находится в 3NF. Однако тот факт, что имеются функциональные зависимости атрибутов отношения от атрибута, являющегося частью первичного ключа, приводит к аномалиям. Например, для того, чтобы изменить имя сотрудника с данным номером согласованным образом, нам потребуется модифицировать все кортежи, включающие его номер. Нормальные формы ER-схемКак и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм. В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскированных" под атрибуты. Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность. В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности. Новые средства разработки файл-серверных приложенийЧем дальше, тем больше файл-серверные приложения сближаются с более развитыми технологиями клиент-серверных приложений. В последнее время появилась целая серия программных продуктов, позиционируемая одновременно как средства "легкой" разработки приложений для персональных компьютеров, так и более "тяжеловесной" разработки приложений в технологии "клиент-сервер". Это и хорошо, поскольку позволяет плавно изменять технологию. Объектный подходДля того, чтобы можно было правильно понять материал следующих разделов этой части, кратко обсудим основные понятия объектно-ориентированного подхода. Основным является понятие объекта - неразрывной совокупности данных (состояния объекта) и набора видимых за пределами объекта процедур, осуществляющих доступ к этим данным (методов объекта). Очень важно то, что после своего создания объект получает генерируемый соответствующей программной системой уникальный идентификатор, который не изменяется за все время существования объекта. В классическом объектно-ориентированном подходе объекты инкапсулированы, т.е. доступ к состоянию объекта возможен только через его методы. Каждый объект относится к некоторому объектному типу (классу), в котором определены как внутренняя структура данных любого объекта этого типа, так и программный код методов такого объекта. Поддерживается понятие наследования объектных типов. Это означает, что при разработке нового типа можно объявить его наследником уже существующего объектного типа, и тогда в новом типе будут считаться определенными структура данных типа-предка и его набор методов. В типе-наследнике можно переопределить структуру данных и код методов типа-предка, а также добавить новые переменные состояния и методы. Наследование может быть одиночным (у каждого типа-наследника может быть только один предок) или множественным (при порождении нового типа разрешается использовать в качестве предков произвольное количество существующих объектных типов). В результате набор объектных типов образует ориентированный ациклический граф (как правило, дерево) в соответствии с отношением наследования. Считается, что объект, относящийся к объектному типу потомка, одновременно является объектом типа любого из предков этого потомка. Другими словами, если используется объект некоторого объектного типа, у которого есть типы-наследники, то до момента реального выполнения метода реально неизвестен программный код этого метода. Поэтому в объектно-ориентированных программных системах обычно используется позднее (отложенное) связывание с используемыми объектами. С этим же связано понятие объектного полиморфизма. Когда в программе вызывается метод объекта некоторого типа, вызывающий объект на самом деле не знает, какую процедуру он вызывает. Все зависит от способа определения типов-наследников. Перечисленные свойства делают объектно-ориентированный подход пригодным и выигрышным для использования во многих областях: операционных системах, системах управления базами данных, системах программирования, системах проектирования и т.д. В том числе, как мы уже упоминали выше, объектно-ориентированный подход все чаще применяется для интеграции разнородных информационно-вычислительных ресурсов. Далее мы главным образом будем рассматривать именно этот аспект. Обязательная (mandatory) связьописывает связь между "независимой" и "зависимой" сущностями. Все экземпляры зависимой ("обязательной") сущности могут существовать только при наличии экземпляров независимой ("необязательной") сущности, т.е. экземпляр "обязательной" сущности может существовать только при условии существования определенного экземпляра "необязательной" сущности. В примере (рисунок 4.21) подразумевается, что каждый автомобиль имеет по крайней мере одного водителя, но не каждый служащий управляет машиной.
 Рис. 4.21. Обязательная связь В Общая характеристика современных средствВ индустрии СУБД для персональных компьютеров отразились тенденции нормализации систем (Rightsizing). В последнее время в этой области происходили два встречных процесса: (1) разукрупнение серверов БД - появление новых версий серверов БД Informix, Oracle и т.д. сначала в варианте для рабочих групп, а потом облегченные версии для одиночных персональных компьютеров; (2) укрупнение СУБД для персональных компьютеров - новые "персональные" СУБД и связанные с ними инструментальные средства развивались в сторону "истинно реляционных" СУБД, т.е. серверов БД, приложений клиент-сервер и инструментальных средств программирования 4GL и быстрой разработки RAD. Новые СУБД для персональных компьютеров и соответствующие инструментальные средства разработки файл-серверных приложений обладают перечисленными ниже общими чертами. Визуальный характер программирования приложений особенно в части создания диалогового графического интерфейса пользователя. Это множество поддерживаемых диалоговых объектов, поддержка механизма drag-and-drop и наличие мастеров, помогающих реализовать сложные процедуры. Управляемость приложений в соответствии с событиями диалога и обеспечение доступа к БД позволяет строить гибкий интерфейс пользователя и поддерживать ссылочную целостность БД. Встроенная поддержка языка структурированных запросов SQL (Standard Query Language) закладывает возможность масштабирования создаваемых файл-серверных приложений до уровня приложений клиент-сервер. Имеется возможность построения приложений клиент-сервер за счет реализации доступа к серверам БД напрямую или через интерфейс ODBC для открытого взаимодействия с базами данных. Использование объектно-ориентированного языка разработки приложений (по крайней мере в части диалога) позволяет широко использовать механизм наследования и тем самым использовать ранее произведенные программные компоненты. Поддержка компонентно-ориентированного программирования дает возможность расширения приложений за счет использования готовых внешних визуальных объектов типа VBX и OCX (ActiveX). "Истинно реляционная" база данных представляет собой объединенный набор файлов, содержащий таблицы, индексы и т.п., что облегчает сопровождение БД и приложений и является основой для поддержки целостности данных. Поддерживается общий для информационной системы словарь данных (data dictionary), который содержит описание структуры БД, типы полей, правила поддержки ограничений целостности и т.п. Поддержка целостности БД (данных, ссылок и транзакций) позволяет создавать приложения с необходимым уровнем надежности и сохранности данных. Возможности серверных процедур обработки (триггеров и хранимых процедур) закладывают основу для масштабирования приложений, позволяют гибко распределять прикладную логику между клиентом и сервером при переходе к архитектуре клиент-сервер. Хранение в БД описания проекта создаваемого приложения является прообразом репозитория инструментальных средств быстрой разработки RAD и CASE-систем. Рассмотрим подробнее несколько примеров сравнительно новых инструментальных средств: MS Access 2.0, Visual FoxPro и CA-VisualObjects. Одиночные операторы манипулирования даннымиКаждый из операторов этой группы является абсолютно независимым от какого бы то ни было другого оператора. Ограничение по ссылкамОграничение по ссылкам от заданного набора столбцов CT таблицы T на заданный набор столбцов CT1 некоторой определенной к этому моменту таблицы T1 определяет условие на содержимое обеих этих таблиц, при котором ссылки можно считать корректными. Если список столбцов CT1 явно специфицирован в определении ограничения по ссылкам, то требуется, чтобы этот список явно входил в какое-либо определение уникальности таблицы T1. Если же список CT1 не специфицирован явно в определении ограничения по ссылкам таблицы T, то требуется, чтобы в определении таблицы T1 присутствовало определение первичного ключа, и список CT1 неявно полагается совпадающим со списком имен столбцов из определения первичного ключа таблицы T1. Имена столбцов списков CT и CT1 должны именовать столбцы таблиц T и T1 соответственно и не должны появляться в списках более одного раза. Списки столбцов CT и CT1 должны содержать одинаковое число элементов, и столбец таблицы T, идентифицируемый i-ым элементом списка CT должен иметь тот же тип, что столбец таблицы T1, идентифицируемый i-ым элементом списка CT1. По определению, таблицы T и T1 удовлетворяют заданному ограничению по ссылкам, если для каждой строки s таблицы T такой, что все значения столбцов s, идентифицируемых списком CT, не являются неопределенными, существует строка s1 таблицы T1 такая, что значения столбцов s1, идентифицируемых списком CT1, позиционно равны значениям столбцов s, идентифицируемых списком CT. По человечески это можно сформулировать так: ограничение по ссылкам удовлетворяется, если для каждой корректной ссылки существует объект, на который она ссылается. В привычной программистам терминологии, ограничение по ссылкам не позволяет производить "висячие" ссылки, не ведущие ни к какому объекту. Ограничение уникальностиКаждое имя столбца в списке уникальности должно именовать столбец T и не должно входить в этот список более одного раза. При определении столбца, входящего в список уникальности, должно быть указано ограничение столбца NO NULL. Среди ограничений уникальности T не должно быть более одного определения первичного ключа (ограничения уникальности с ключевым словом RIMARY KEY). Действие ограничения уникальности состоит в том, что в таблице T не допускается появление двух или более строк, значения столбцов уникальности которых совпадают. Оператор чтения очередной строки курсораСинтаксис оператора чтения следующий: <fetch statement> ::= FETCH <cursor name> INTO <fetch target list> <fetch target list> ::= <target specification>[{,<target specification>}...] В операторе чтения указывается имя курсора и обязательный раздел INTO, содержащий список спецификаций назначения (список имен переменных основной программы в случае встроенного SQL или имен "выходных" параметров в случае модуля SQL). Число и типы данных в списке назначений должны совпадать с числом и типами данных списка выборки спецификации курсора. Любой открытый курсор всегда имеет позицию: он может быть установлен перед некоторой строкой результирующей таблицы (перед первой строкой сразу после открытия курсора), на некоторую строку результата или за последней строкой результата. Если таблица, на которую указывает курсор, является пустой, или курсор позиционирован на последнюю строку или за ней, то при выполнении оператора чтения курсор устанавливается в позицию после последней строки, параметру SQLCODE присваивается значение 100, никакие значения не присваиваются целям, идентифицированным в разделе INTO. Если курсор установлен в позицию перед строкой, то он устанавливается на эту строку, и значения этой строки присваиваются соответствующим целям. Если курсор установлен на строку r, отличную от последней строки, то курсор устанавливается на строку, непосредственно следующую за строкой r, и значения из этой следующей строки присваиваются соответствующим целям. Возникает естественный вопрос, каким образом можно параметризовать курсор неопределенным значением или узнать, что выбранное из очередной строки значение является неопределенным. В SQL/89 это достигается за счет использования, так называемых, индикаторных параметров и переменных. Если известно, что значение, передаваемое из основной программы СУБД или принимаемое основной программой от СУБД, может быть неопределенным, и этот факт интересует прикладного программиста, то спецификация параметра или переменной в операторе SQL имеет вид: <parameter name> [INDICATOR]<parameter name> при спецификации параметра, и <embedded variable name>[INDICATOR]<embedded variable name> при спецификации переменной. Отрицательное значение индикаторного параметра или индикаторной переменной (они должны быть целого типа) соответствует неопределенному значению параметра или переменной. Оператор чтения строки по курсору, связанному с динамически подготовленным оператором выборки<dynamic fetch statement> ::= FETCH [[<fetch orientation>] FROM] <dynamic cursor name> <using clause> По сути, оператор чтения по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задается размещение значений текущей строки результирующей таблицы. Кроме того, имя курсора может задаваться через переменную. Оператор объявления курсораДля удобства мы повторим здесь синтаксические правила объявления курсора, приводившиеся раньше: <declare cursor> ::= DECLARE <cursor name> CURSOR FOR <cursor specification> <cursor specification> ::= <query expression> [<order by clause>...] <query expression> ::= <query term> <query expression> UNION [ALL] <query term> <query term> ::= <query specification> (<query expression>) <order by clause> ::= ORDER BY <sort specification> [{,<sort specification>}...] <sort specification> ::= { <unsigned integer> <column specification> } [ASC DESC] В объявлении курсора могут задаваться запросы наиболее общего вида с возможностью выполнения операции UNION и сортировкой конечного результата. Этот оператор не является выполняемым, он только связывает имя курсора со спецификацией курсора. Оператор объявления курсора над динамически подготовленным оператором выборки<dynamic declare cursor> ::= DECLARE <cursor name> [INSENSITIVE] [SCROLL] CURSOR FOR <statement name> Как определяется в новом стандарте, для всех операторов DECLARE CURSOR, курсоры фактически создаются при начале транзакции и уничтожаются при ее завершении. Заметим, что в этом операторе <cursor name> и <statement name> - прямо заданные идентификаторы. Оператор определения курсора над динамически подготовленным оператором выборки<allocate cursor statement> ::= ALLOCATE <extended cursor name> [INSENSITIVE] [SCROLL] CURSOR FOR <extended statement name> <extended cursor name> ::= [<scope option>] <simple value specification> Курсоры, определяемые с помощью оператора ALLOCATE CURSOR, фактически создаются при выполнении такого оператора и уничтожаются при выполнении оператора DEALLOCATE PREPARE или при конце транзакции. В этом операторе имена курсора и подготовленного оператора SQL могут задаваться не только в литеральной форме, но и через переменные. <scope option> относится к области видимости имен: в пределах текущего модуля или в пределах текущей сессии. Оператор определения схемыВ соответствии с правилами SQL/89 каждая таблица данной БД имеет простое и квалифицированное имена. В качестве квалификатора имени выступает "идентификатор полномочий" таблицы, который обычно в реализациях совпадает с именем некоторого пользователя, квалифицированное имя таблицы имеет вид: <идентификатор полномочий>.<простое имя> Подход к определению схемы в SQL/89 состоит в том, что все таблицы с одним идентификатором полномочий создаются (определяются) путем выполнения одного оператора определения схемы. При этом в стандарте не определяется способ выполнения оператора определения схемы: должен ли он выполняться только в интерактивном режиме или может быть встроен в программу, написанную на традиционном языке программирования. В операторе определения схемы содержится идентификатор полномочий и список элементов схемы, каждый из которых может быть определением таблицы, определением представления (view) или определением привилегий. Каждое из этих определений представляется отдельным оператором SQL/89, но все они, как уже говорилось, должны быть встроены в оператор определения схемы. Для этих операторов мы приведем синтаксис, поскольку это позволит более четко описать их особенности. Оператор освобождения памяти из-под дескриптора<deallocate descriptor statement> ::= DEALLOCATE DESCRIPTOR <descriptor name> Выполнение этого оператора приводит к освобождению памяти из-под ранее выделенного дескриптора. После этого использование имени дескриптора незаконно в любом операторе, кроме ALLOCATE DESCRIPTOR. Оператор отказа от подготовленного оператора<deallocate prepared statement> ::= DEALLOCATE PREPARE <SQL statement name> Выполнение этого оператора приводит к тому, что ранее подготовленный оператор SQL, связанный с указанным именем оператора, ликвидируется, и соответственно, имя оператора становится неопределенным. Если подготовленный оператор являлся оператором выборки, и к моменту выполнения оператора DEALLOCATE существовал открытый курсор, связанный с именем подготовленного оператора, то оператор DEALLOCATE возвращает код ошибки. Если же для подготовленного оператора выборки существовал неоткрытый курсор, образованный с помощью оператора ALLOCATE CURSOR, то этот курсор ликвидируется. Если курсор объявлялся оператором DECLARE CURSOR, то такой курсор переходит в состояние, существовавшее до выполнения оператора PREPARE. Если с курсором был связан подготовленный оператор (динамический DELETE или UPDATE), то для этих операторов выполняется неявный оператор DEALLOCATE. Оператор открытия курсораОператор описывается следующим синтаксическим правилом: <open statement> ::= OPEN <cursor name> В реализациях встроенного SQL обычно требуется, чтобы объявление курсора текстуально предшествовало оператору открытия курсора. Оператор открытия курсора должен быть первым в серии выполняемых операторов, связанных с заданным курсором. При выполнении этого оператора производится подготовка курсора к работе над ним. В частности, в этот момент производится связывание спецификации курсора со значениями переменных основного языка в случае встроенного SQL или параметров в случае модуля. В большинстве реализаций в случае встроенного SQL именно выполнение оператора открытия курсора приводит к компиляции спецификации курсора. Следующие операторы можно выполнять над открытым курсором в произвольном порядке. Оператор открытия курсора, связанного с динамически подготовленным оператором выборки<dynamic open statement> ::= OPEN <dynamic cursor name> [<using clause>] По сути, оператор открытия курсора, связанного с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задаются фактические параметры оператора выборки. Кроме того, имя курсора может задаваться через переменную. Оператор подготовки<prepare statement> ::= PREPARE <SQL statement name> FROM <SQL statement variable> <SQL statement variable> ::= <simple target specification> <preparable statement> ::= <preparable SQL data statement> <preparable SQL schema statement> <preparable SQL transaction statement> <preparable SQL session statement> <preparable implementation-defined statement> <preparable SQL data statement> ::= <delete statement: searched> <dynamic single row select statement> <insert statement> <dynamic select statement> <update statement: searched> <preparable dynamic delete statement: positioned> <preparable dynamic update statement: positioned> <preparable SQL schema statement> ::= <SQL schema statement> <preparable SQL transaction statement> ::= <SQL transaction statement> <preparable SQL session statement> ::= <SQL session statement> <dynamic select statement> ::= <cursor specification> <dynamic simple row select statement> ::= <query specification> <SQL statement name> ::= <statement name> <extended statement name> <extended statement name> ::= [scope option] <simple value specification> <cursor specification> ::= <query expression> [<order by clause>] [<updatability clause>] <updatability clause> ::= FOR { READ ONLY UPDATE [ OF <column name list> ] } <query expression> ::= <non-join query expression> <joined table> <query specification> ::= SELECT [<set quantifier>] <select list> <table expression> <set quantifier> ::= DISTINCT ALL Оператор PREPARE вызывает компиляцию и построение плана выполнения заданного в текстовой форме оператора SQL. После успешного выполнения оператора PREPARE с подготовленным оператором связывается указанное (литерально или косвенно) имя этого оператора, которое потом может быть использовано в операторах DESCRIBE, EXECUTE, OPEN CURSOR, ALLOCATE CURSOR и DEALLOCATE PREPARE. Эта связь сохраняется до явного выполнения оператора DEALLOCATE PREPARE. Оператор подготовки с немедленным выполнением<execute immediate statement> ::= EXECUTE IMMEDIATE <SQL statement variable> При выполнении оператора EXECUTE IMMEDIATE производится подготовка и немедленное выполнение заданного в текстовой форме оператора SQL. При этом подготавливаемый оператор не должен быть оператором выборки, не должен содержать формальных параметров и комментариев. Оператор поискового удаленияОператор описывается следующим синтаксическим правилом: <delete statement: searched> ::= DELETE FROM <table name> WHERE [<search condition>] Таблица T, указанная в разделе FROM оператора DELETE, должна быть изменяемой. На условие поиска накладывается то условие, что на таблицу T не должны содержаться ссылки ни в каком вложенном подзапросе предикатов раздела WHERE. Фактически оператор выполняется следующим образом: последовательно просматриваются все строки таблицы T, и те строки, для которых результатом вычисления условия выборки является true, удаляются из таблицы T. При отсутствии раздела WHERE удаляются все строки таблицы T. Оператор поисковой модификацииОператор обладает следующим синтаксисом: <update statement: searched> ::= UPDATE <table name> SET <set clause: searched> [{,<set clause: searched>}...] [WHERE <search conditions>] <set clause: searched> ::= <object column: searched> = { <value expression> NULL } <object column: searched> ::= <column name> Таблица T, указанная в операторе UPDATE, должна быть изменяемой. На условие поиска накладывается то условие, что на таблицу T не должны содержаться ссылки ни в каком вложенном подзапросе предикатов раздела WHERE. Оператор фактически выполняется следующим образом: таблица T последовательно просматривается, и каждая строка, для которой результатом вычисления условия поиска является true, изменяется в соответствии с разделом SET. Если арифметическое выражение в разделе SET содержит ссылки на столбцы таблицы T, то при вычислении арифметического выражения используются значения столбцов текущей строки до их модификации. Оператор получения информации из области дескриптора SQL<get descriptor statement> ::= GET DESCRIPTOR <descriptor name> <get descriptor information> <get descriptor information> ::= <get count> VALUE <item number> <get item information> {<comma> <get item information>}...] <get count> ::= <simple target specification 1> <equals operator> COUNT <get item information> ::= <simple target specification 2> <equals operator> <descriptor item name> <item number> ::= <simple value specification> <simple target specification 1> ::= <simple target specification> <simple target specification 2> ::= <simple target specification> <descriptor item name> ::= TYPE LENGHT OCTET_LENGHT RETURNED_LENGHT RETURNED_OCTET_LENGHT PRECISION SCALE DATETIME_INTERVAL_CODE DATATIME_INTERVAL_PRECISION NULLABLE INDICATOR DATA NAME UNNAMED COLLATION_CATALOG COLLATION_SCHEMA COLLATION_NAME CHARACTER_SET_CATALOG CHARACTER_SET_SCHEMA CHARACTER_SET_NAME <simple target specification> ::= <parameter name> <embedded variable name> Оператор GET DESCRIPTOR служит для выборки описательной информации, ранее размещенной в дескрипторе с помощью оператора DESCRIBE. За одно выполнение оператора можно получить либо число заполненных элементов дескриптора (COUNT), либо информацию, содержащуюся в одном из заполненных элементов. Оператор позиционного удаленияСинтаксис этого оператора следующий: <delete statement: positioned> ::= DELETE FROM <table name> WHERE CURRENT OF <cursor name> Если указанный в операторе курсор открыт и установлен на некоторую строку, и курсор определяет изменяемую таблицу, то текущая строка курсора удаляется, а он позиционируется перед следующей строкой. Таблица, указанная в разделе FROM оператора DELETE, должна быть таблицей, указанной в самом внешнем разделе FROM спецификации курсора. <dynamic delete statement: positioned> ::= DELETE FROM <table name> WHERE CURRENT OF <dynamic cursor name> По сути, оператор позиционного удаления по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную. |