Блокировка
Каждая СУБД должна предоставлять некоторую форму блокировки объектов для того, чтобы обеспечить безопасный параллельный доступ и обновление. Ранние ОО-СУБД поддерживали блокировку на уровне страниц, при которой границы блокируемой области определялись операционной системой. Это было неудобно как для больших объектов (которые могут занимать несколько страниц), так и для маленьких (которых может быть много на одной странице, так что блокировка одного из них повлечет блокировку и остальных). Новые системы предлагают блокировку на уровне объекта, позволяя приложению клиента блокировать объекты индивидуально.
Последние усилия направлены на минимизацию размера блокировки в процессе реального выполнения, поскольку блокировка может вызвать конфликты и замедление выполнения операций БД. Оптимистическая блокировка - это общее название целого класса методов, которые пытаются устранить априорное навешивание замка на объект, выполняя вместо этого спорные операции на копии объекта, откладывая насколько возможно обновление главной копии, затем блокируют ее, согласовывая конфликтующие обновления. Мы увидим далее пример оптимистической блокировки в системе Matisse.
Длинные транзакции
Понятие транзакции уже давно является очень важным для СУБД, но классические механизмы транзакций ориентированы на короткие транзакции, которые начинаются и завершаются одной операцией, выполняемой одним пользователем во время одной сессии работы компьютерной системы. Исходным примером, процитированным в начале этой лекции, служит банковский перевод денег с одного счета на другой; он является транзакцией, поскольку требует либо полного выполнения обеих операций (снятия денег с одного счета и зачисления их на другой), либо (при неудаче) - сохранения исходного состояния. Время, занимаемое этой транзакцией, составляет несколько секунд (даже меньше, если не учитывать взаимодействие с пользователем).
У приложений, связанных с проектированием сложных систем, таких как CAD-CAM (системы автоматизированного проектирования и производства инженерной продукции) или системы автоматизированного проектирования ПО, возникает потребность в длинных транзакциях, которые могут выполняться в течение дней или даже месяцев. Например, в процессе проектирования автомобиля одна из групп инженеров может прекратить работу над частью карбюратора, чтобы внести какие-то изменения, и вернуться к ней через неделю или две. У такой операции имеются все свойства транзакции, но методы, разработанные для коротких транзакций, здесь напрямую не применимы.
Область разработки ПО имеет очевидную потребность в длинных транзакциях, возникающую всякий раз, когда несколько человек или команд работают над общим набором модулей. Интересно, что технология БД не получила широкого распространения (несмотря на многие предложения в литературе) в сфере разработки ПО. Вместо этого, разрабатывались собственные средства управления конфигурациями (configuration management), которые ориентировались на специфические запросы разработки компонентов ПО, а также дублировали некоторые стандартные функции СУБД, как правило, не используя достижений технологии БД. Эта, на первый взгляд, странная ситуация имеет вполне вероятное простое объяснение: отсутствие длинных транзакций в традиционных СУБД.
Хотя длинные транзакции концептуально могут и не требовать использования объектной технологии, усилия последнего времени по их поддержке пришли со стороны ОО-СУБД, некоторые из которых предлагают способ проверки любого объекта как в базе данных, так и вне нее.
Дополнительные возможности
Имеется много желательных свойств БД, не входящих в пороговую модель. Большинство коммерческих систем предлагают, по крайней мере, некоторые из них.
Первая категория включает непосредственную поддержку более глубоких свойств ОО-метода: наследования (одиночного или множественного), типизации, динамического связывания. Не нужно подробней разъяснять эти свойства читателям данной книги. Другие возможности, которые мы кратко рассмотрим ниже, включают: версии объектов, эволюцию схемы, длинные транзакции, блокировка, ОО-запросы.
Форматы сохранения
У процедуры store имеется несколько вариантов. Один, basic_store (базовое_сохранение), сохраняет объекты для их последующего возвращения в ту же систему, работающую на машине той же архитектуры, в процессе того же или последующего ее исполнения. Эти предположения позволяют использовать наиболее компактную форму представления объектов.
Другой вариант, independent_store (независимое_сохранение), обходится без этих предположений; представление объекта в нем не зависит от платформы и от системы. Поэтому оно занимает несколько больше места, так как использует переносимое представление для чисел с плавающей точкой и для других числовых значений, а также должно включать некоторую простую информацию о классах системы. Но он важен для систем типа клиент-сервер, которые должны обмениваться потенциально большими и сложными наборами объектов, находящимися на машинах весьма разных архитектур, работающих в различных системах. Например, сервер на рабочей станции и клиент на PC могут выполнять два разных приложения и взаимодействовать с помощью библиотеки Net. Сервер приложения выполняет основные вычисления, а приложение клиента реализует интерфейс пользователя, используя графическую библиотеку, например Vision.
Заметим, что только сохранение требует нескольких процедур - basic_store, independent_store. Хотя реализация операции возврата для каждого формата своя, всегда можно использовать один компонент retrieved, реализация которого определит формат возвращаемых данных, используемый в файле или сети, и автоматически применит соответствующий алгоритм извлечения.
Идентичность объектов
Простота реляционной модели частично объясняется тем, что объекты однозначно идентифицируются значениями своих атрибутов. Отношение (таблица) является подмножеством декартового произведения A x B x ... некоторых множеств A, B, ...; иными словами, каждый элемент отношения, каждый объект, это кортеж <a1, b1, ...>, в котором a1 принадлежит A и т. д. Поэтому он не существует вне своего значения, в частности, вставка объекта в отношение не будет иметь никакого эффекта, если в отношении уже имелся идентичный кортеж. Например, вставка <"The Red and the Black", 1830, 341, "STENDHAL"> в приведенное выше отношение BOOKS не приведет к изменению этого отношения. Это сильно отличается от динамичной модели ОО-вычислений, в которой могут существовать два идентичных объекта.
Напомним, что отношение equal (obj1, obj2) истинно, если obj1 и obj2 - это ссылки, присоединенные к этим объектам, но равенство obj1 = obj2 будет ложным.
Быть идентичными - не значит быть одними и теми же (спросите об этом близнецов). Такая способность различать два этих понятия частично определяет силу моделирования в ОО-технологии. Она основана на понятии идентичности объекта: всякий объект существует независимо от его содержания.
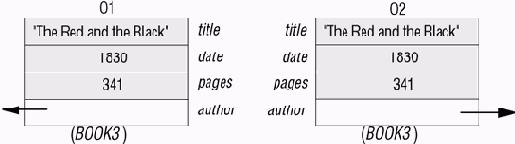
Рис. 13.6. Отдельные, но равные (обе нижние ссылки присоединены к одному объекту)
|
Посетителям Императорского дворца в Киото говорят, что эти здания очень древние и каждое перестраивается приблизительно раз в сто лет. С учетом понятия идентичности объекта в этом нет никакого противоречия: объект остается тем же, даже если его содержание меняется. Вы та же личность, что и десять лет назад, хотя ни одной из молекул, составляющих ваше тело в то время, сейчас не осталось. |
Разумеется, в реляционной модели тоже можно выразить идентичность объектов: достаточно добавить к каждому объекту специальное ключевое поле с уникальным для объектов данного типа значением. Но придется об этом заботиться явно. А в ОО-модели идентичность объектов имеется по умолчанию.
При создании ОО-ПО, не требующего хранить объекты, поддержка идентичности объекта получается почти случайно: в простейшей реализации каждый объект постоянно хранится по некоторому адресу, а ссылки на объект используют этот адрес, который служит неизменяемым идентификатором данного объекта. (Это неверно для более сложных реализаций, например, фирмы ISE, которые могут перемещать объекты в процессе эффективного сбора мусора; в этих реализациях идентичность объекта является более абстрактным понятием.) Если требуется хранить объекты, то идентичность объекта становится важным фактором ОО-модели.
Поддержка идентичности объектов в разделяемых БД приводит к новым проблемам: каждый клиент, которому нужно создавать объекты, должен получать для них уникальные идентификаторы; это значит, что специальный модуль, ответственный за присвоение идентификаторов, должен быть разделяемым ресурсом, что в условиях сильной параллельности создает потенциальное узкое горлышко.
Использование реляционных баз данных с ОО-ПО
Основные понятия реляционных СУБД, кратко описанные выше, демонстрируют явное сходство с основной моделью ОО-вычисления. Можно сопоставить отношению класс, а кортежу этого отношения - объект, экземпляр класса. Нам потребуется библиотечный класс, предоставляющий операции реляционной алгебры (соответствующий встроенному SQL).
Многие ОО-окружения предоставляют такую библиотеку для C++, Smalltalk или для языка этой книги (библиотека Store). Этот подход, который можно назвать объектно-реляционным взаимодействием, был успешно испробован во многих разработках. Он подходит в одном из следующих случаев:
ОО-система должна использовать и, возможно, обновлять существующие общие данные, находящиеся в реляционных базах данных. Тогда нет иного выбора, как использовать объектно-реляционный интерфейс.ОО-система должна сохранять объекты, структура которых хорошо соответствует реляционному взгляду на вещи. (Далее будут объяснены причины, по которым это бывает не всегда.)Если ваши требования к сохраняемости не подпадают под эти случаи, то вы будете испытывать то, что в литературе называют сопротивлением несогласованности (impedance mismatch) между ОО-моделью данных вашей разработки ПО и реляционной моделью данных БД. Тогда полезно будет взглянуть на новейшие разработки в области БД: объектно-ориентированные системы баз данных.
Исправление
Как следует исправлять объект, для которого при возвращении обнаружено рассогласование? Ответ требует аккуратного анализа и более сложного подхода, чем обычно реализуется в существующих системах или предлагается в литературе.
Ситуация такова: механизм возвращения (с помощью компонента retrieved класса STORABLE, соответствующей операции БД или другого доступного примитива) создал в возвращающей системе новый объект, исходя из некоторого сохраненного объекта того же класса, но обнаружил при этом рассогласование. Новый объект в его временном состоянии может быть неправильным, например, он может потерять некоторое поле, присутствовавшее у сохраненного объекта, или приобрести поле, которого не было у оригинала. Рассматривайте его как иностранца без визы.
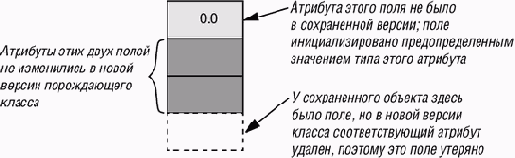
Рис. 13.3. Рассогласование объекта
|
Такое состояние объекта аналогично промежуточному состоянию объекта, создаваемого - вне всяких рассуждений о сохранении - с помощью инструкции создания create x.make (...) сразу после распределения ячеек памяти объекта и инициализации их предопределенными значениями, но перед вызовом make (см. лекцию 8 курса "Основы объектно-ориентированного программирования". На этой стадии у объекта имеются все требуемые компоненты, но он еще не готов быть принятым в обществе, поскольку может иметь неверные значения некоторых полей; как мы видели, официальная цель процедуры make состоит в замене при необходимости предопределенных значений инициализации на значения, обеспечивающие инвариант. |
Предположим для простоты, что метод выявления является структурным и основан на атрибутах (т. е. на определенной выше политике C3), хотя приведенное далее обсуждение распространяется и на другие решения, как номинальные, так и структурные. Рассогласование является следствием изменения свойств атрибутов класса. Можно свести все такие изменения к комбинациям некоторого числа добавлений и удалений атрибутов. На приведенном выше рисунке показано одно добавление и одно удаление.
Удаление атрибута не вызывает никаких трудностей: если в новом классе отсутствует некоторый атрибут старого класса, то соответствующие поля в объекте больше не нужны и их можно просто убрать.
Фактически, процедура correct_mismatch ничего не должна делать с такими полями, поскольку механизм возвращения при создании временного экземпляра нового класса будет их отбрасывать. На рисунке это показано для нижнего поля - скорее, уже не поля - изображенного объекта.
| Можно было бы, конечно, проявить больше заботы об отбрасываемых полях. А что, если они были действительно необходимы, а без них объект потеряет свой смысл? В таком случае нужно иметь более продуманную политику выявления, например, такую, как структурная политика C4, которая учитывает инварианты. |
Вспомним стандартный пример - класс ACCOUNT с атрибутами deposits_list и withdrawals_list. Предположим, в новой версии добавлен атрибут balance. Система, используя новую версию, пытается возвратить некоторый экземпляр, созданный в предыдущей версии.
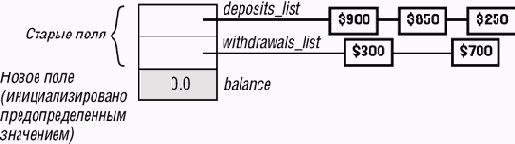
Рис. 13.4. Возвращение объекта account (счет).(Подумайте, что не в порядке на этом рисунке?)
Цель добавления атрибута balance понятна: вместо того, чтобы перевычислять баланс счета по каждому требованию, мы держим его в объекте и обновляем при необходимости. Инвариант нового класса отражает это с помощью предложения вида:
balance = deposits_listltotal - withdrawals_listltotalНо, если применить к полю balance возвращаемого объекта инициализацию по умолчанию, то получится совершенно неправильный результат, в котором поле с балансом счета не согласуется с записями вкладов и расходов. На приведенном рисунке balance из-за инициализации по умолчанию нулевой, а в соответствии со списком вкладов и расходов он должен равняться $1000.
Это показывает важность механизма корректировки correct_mismatch . В данном случае можно просто переопределить эту процедуру:
correct_mismatch is -- Обработать рассогласование объекта, правильно установив balance do balance := deposits_list.total -withdrawals_list.total endЕсли автор нового класса ничего не запланирует на этот случай, то предопределенная версия correct_mismatch возбудит исключение, которое аварийно остановит приложение, если не будет обработано retry (реализующим другую возможность восстановления). Это правильный выход, поскольку продолжение вычисления может нарушить целостность структуры выполняемого объекта и, что еще хуже, структуры сохраненного объекта, например БД. Используя предыдущую метафору, можно сказать, что мы будем отвергать объект до тех пор, пока не сможем присвоить ему надлежащий иммигрантский статус.
Извещение
Что должно произойти после того, как номинальный или структурный механизм выявления выловит рассогласование объекта?
Хотелось бы, чтобы возвращающая система узнала об этом и сумела предпринять необходимые корректирующие действия. Этой проблемой будет заниматься некоторый библиотечный механизм. Класс GENERAL (предок всех классов) должен содержать процедуру:
correct_mismatch is do ...См. полную версию ниже... endи правило, что любое выявленное рассогласование объекта приводит к вызову correct_mismatch (корректировать_рассогласование) на временно возвратившейся версии объекта. Каждый класс может переопределить стандартную версию correct_mismatch аналогично всякому переопределению процедур создания и стандартной обработки исключений default_rescue. Любое переопределение correct_ mismatch должно сохранять инвариант класса.
Что должна делать стандартная (определенная по умолчанию) версия correct_mismatch? Дать ей пустое тело, демонстрируя ненавязчивость, не годится. Это означало бы по умолчанию игнорирование рассогласования, что привело бы к всевозможным ненормальностям в поведении системы. Для глобальной стандартной процедуры лучше возбудить соответствующее исключение:
correct_mismatch is -- Обработка рассогласования объекта при возврате do raise_mismatch_exception endгде процедура, вызываемая в теле, делает то, что подразумевается ее именем. Это может привести к некоторым неожиданным исключениям, но лучше это, чем разрешить рассогласованиям остаться незамеченными. Если в проекте требуется переделать это предопределенное поведение, например, выполнять пустую инструкцию, а не возбуждать исключение, то всегда можно переопределить correct_mismatch, на свой страх и риск, в классе ANY. (Как вы помните, определенные разработчиками классы наследуют GENERAL не прямо, а через класс ANY, который может быть переделан при проектировании или инсталляции.)
|
Для большей гибкости имеется также компонент mismatch_information (информация_о_рассогласовании) типа ANY, определенный как однократная функция. Процедура set_mismatch_information (info: ANY) позволяет передать в correct_mismatch больше информации, например, о различных предыдущих версиях класса. |
Если вы предполагаете, что у объектов некоторого класса возникнут рассогласования, то лучше не рассчитывать на обработку исключений по умолчанию, а переопределить correct_mismatch так, чтобы сразу изменять возвращаемый объект. Это приводит нас к последней задаче - исправлению.
Является ли "ОО-база данных" оксюмороном?
Понятие базы данных произошло от взгляда на мир, в центре которого сидят Данные, а расположенным вокруг программам разрешены доступ и модификация этих Данных:

Рис. 13.7. Взгляд со стороны баз данных
Однако в объектной технологии мы научились понимать данные как сущности, полностью определяемые применяемыми к ним операциями:

Рис. 13.8. ОО-взгляд
Эти два взгляда кажутся несовместимыми! Понятие данных, существующих независимо от обрабатывающих их программ ("независимость данных", догмат, повторяемый на первых страницах любой книги по БД) является проклятием для ОО-разработчика. Должны ли мы считать выражение "ОО-база данных" оксюмороном?1)
Возможно, нет, но, быть может, стоит понять, как в догматическом ОО-контексте можно получить эффект баз данных, реально не имея их. Если мы дадим определение (упрощая до самого существенного данное ранее в этой лекции определение БД)
БАЗА ДАННЫХ = СОХРАНЯЕМОСТЬ + РАЗДЕЛЕНИЕ ДАННЫХ,то догматический взгляд будет рассматривать второй компонент, разделение данных, как несовместимый с ОО-идеями, и сосредоточится только на сохраняемости. Но тогда можно подойти к разделению данных, используя другой метод - параллелизм! Это показано на следующем рисунке.
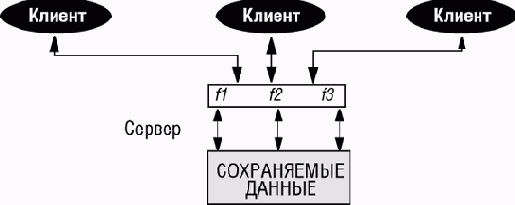
Рис. 13.9. Отделение сохраняемости от разделения данных
Следуя ОО-принципам, сохраняемые данные реализуются как множество объектов - экземпляров некоторых абстрактных типов данных - и управляются некоторой серверной системой. Системы клиентов, которым требуется работать с данными, будут делать это через сервер. Так как эта схема требует разделения и параллельного доступа, то клиенты будут рассматривать сервер как сепаратный в смысле, определенном при обсуждении параллельности в лекции 12. Например:
flights: separate FLIGHT_DATABASE; ... flight_details (f: separate FLIGHT_DATABASE; rf: REQUESTED_FLIGHTS): FLIGHT is do Result := f.flight_details (rf) end reserve (f: separate FLIGHT_DATABASE; r: RESERVATION) is do f.reserve (r); status := f.status endТогда на стороне сервера не требуется никакого механизма разделения, а только общий механизм сохранения.
Нам могут также понадобиться средства и методы для поддержки версий объектов, но они, по существу, относятся к вопросам сохраняемости объектов, а не к базам данных.
В этом случае механизм сохранения может стать чрезвычайно простым, отбросив многое из багажа БД. Можно даже считать, что все объекты по умолчанию являются постоянно хранимыми, а временные объекты становятся исключением, обрабатываемым механизмом, обобщающим сбор мусора. Такой подход, который невозможно было представить при изобретении БД, становится менее абсурдным при постоянном уменьшении стоимости памяти и росте доступности 64-битовых виртуальных адресных пространств, в которых, как было уже замечено в [Sombrero-Web], "можно создавать каждую секунду новый 4-гигабайтный объект (вся память обычного 32-битного процессора) в течение 136 лет и все еще не исчерпать доступные адреса. Этого достаточно, чтобы сохранить все данные, связанные с почти любым приложением на протяжении всего его существования".
Все это весьма умозрительно и нет никаких оснований для того, чтобы отказываться от традиционного понятия БД. Не следует также немедленно мчаться и продавать акции компаний, создающих ОО-БД. Рассматривайте это обсуждение как интеллектуальное упражнение: приглашение прозондировать будущее общепринятого понятия ОО-БД, проверив, может ли существующий подход по-настоящему успешно справиться со страшным сопротивлением несогласованности между методом разработки ПО и механизмами, поддерживающими накопление и хранение данных.
Эволюция схемы
Этот общий вопрос возникает при всех подходах к ОО-сохраняемости. Классы могут меняться. Что произойдет, если изменится класс, экземпляры которого находятся где-то на постоянном хранении? Этот вопрос называют проблемой эволюции схемы.
|
Слово схема (schema) пришло из мира реляционных баз данных, где она задает архитектуру БД: множество ее отношений с указанием того, что называется их типами, - число полей и тип каждого поля. В ОО-контексте схема тоже будет множеством типов, определяемых в этом случае классами. |
Хотя некоторые средства разработки и системы баз данных обладают интересными средствами для эволюции ОО-схем, ни одно из них не дает полностью удовлетворительного решения. Давайте, определим компоненты полного подхода.
Будет полезно ввести некоторую точную терминологию. Эволюция схемы имеет место, если хотя бы один класс системы, возвращающей объекты (возвращающая система), отличается от своего прототипа в системе, сохранившей эти объекты (сохраняющая система). Рассогласование при возврате объекта или просто рассогласование объекта имеет место, когда возвращающая система реально возвращает некоторый объект, у которого изменился породивший его класс. Рассогласование объекта - это следствие эволюции схемы одного или нескольких классов, отражающееся на конкретном объекте.
|
Напомним, несмотря на термины "сохраняющая система" и "возвращающая система" наше обсуждение применимо не только к сохранению и возврату, использующим файлы и БД, но также и к передаче объектов по сети, как в библиотеке Net. В этом случае более аккуратными терминами были бы "посылающая система" и "получающая система". |
Для упрощения обсуждения примем обычное предположение, что программная система не изменяется в процессе ее выполнения. Это означает, что все сохраненные экземпляры класса относятся к одной и той же версии, поэтому во время возвращения либо все они приведут к рассогласованию, либо ни один из них не будет рассогласован. Это предположение не слишком ограничительное, оно не исключает случая баз данных, которые содержат экземпляры многих разных версий одного класса, созданные различными выполнениями системы.
Matisse
MATISSE от фирмы ADB Inc., - это ОО-СУБД, поддерживающая C, C++, Smalltalk и нотацию данной книги.
Matisse - это смелая разработка со многими необычными идеями. Она ориентирована на большие базы данных с богатой семантической структурой и может манипулировать с очень большими объектами, такими как изображения, фильмы и звуки. Хотя она поддерживает основные ОО-понятия, в частности, множественное наследование, но не налагает сильных ограничений на модель данных, а скорее служит мощной машиной ОО-БД. Перечислим некоторые из ее сильных сторон:
оригинальный метод представления, позволяющий разбивать объект - особенно большой объект - на части, помещаемые на нескольких дисках, и таким образом оптимизировать время доступа;оптимизированное размещение объекта на дисках;механизм автоматического дублирования, обеспечивающий программное решение проблемы устойчивости к машинным сбоям: объекты (а не сами диски) могут быть дублированы и автоматически восстановлены в случае сбоя на диске;встроенный механизм поддержки версий объектов (см. ниже);поддержка транзакций;Поддержка архитектуры клиент-сервер, в которой центральный сервер управляет данными возможно большего числа клиентов и ведет "кэш" недавно использованных объектов.Matisse использует оригинальный подход к проблеме минимизации блокировок. Многие системы применяют следующее правило взаимного исключения: несколько клиентов могут читать объект одновременно, но как только один из клиентов начинает писать, ни один из других не может читать или писать. Причина, объясненная в лекции о параллельности, состоит в сохранении целостности объекта, выраженной инвариантами класса. Если разрешить одновременную запись двум клиентам, то объект может стать несовместным, а если некоторый клиент находится в середине процесса записи, то объект может оказаться в нестабильном состоянии (не удовлетворяющем инварианту), так что другой клиент, который его в этот момент читает, получит неверный результат.
Очевидно, что блокировка вида писатель-писатель необходима.
Что касается исключений вида писатель-читатель, то некоторые системы их не придерживаются, разрешая операции чтения даже при наличии блокировки записи. Такие операции уместно назвать грязным чтением (dirty reads).
Matisse, чьи создатели явно преследовали цель минимизации блокировок, предложил радикальное решение этого вопроса, основанное на организации управления объектами: никаких операций записи. Вместо изменения существующего объекта операция записи (из ПО клиента) создает новый объект. В результате можно читать объекты без всяких блокировок: у вас всегда будет доступ к некоторой версии БД, на которую не повлияли операции записи, которые могли произойти после начала вашего чтения. Вы также можете получить доступ к большому числу объектов с гарантией, что все они принадлежат одной и той же версии БД, в то время как при традиционном подходе для достижения того же результата потребовалось бы использовать глобальные блокировки или транзакции, что привело бы к большой потере эффективности.
Следствием такой политики является возможность возврата к предыдущим версиям объекта или самой БД. По умолчанию, старые версии сохраняются, но система предоставляет "сборщик версий", позволяющий избавляться от нежелательных версий.
Система Matisse предоставляет интересные возможности для работы с отношениями. Например, если у класса EMPLOYEE (СЛУЖАЩИЙ) имеется атрибут supervisor (руководитель): MANAGER, то Matisse (по требованию разработчика) автоматически отслеживает обратные связи, так что можно получить доступ не только к руководителю служащего, но также и ко всем служащим, подчиненным данному руководителю. Кроме того, возможны запросы, ищущие объекты по ключевым словам.
На чем застопорились реляционные БД
Было бы абсурдом отрицать вклад систем реляционных БД. (На самом деле в то время как первые публикации по ОО-БД в восьмидесятых склонялись к критике реляционной технологии, современная тенденция состоит в том, чтобы рассматривать эти два подхода как взаимодополняющие.) Реляционные системы являются одним из важнейших компонентов роста информационных технологий, начиная с семидесятых, и будут оставаться им еще долгое время. Они хорошо приспособились к ситуациям, связанным с данными (возможно, больших размеров), в которых:
R1 структура данных регулярна: все объекты данного типа имеют одинаковое число и типы компонентов;R2 эта структура простая: для типов компонентов имеется небольшое множество заранее определенных возможностей;R3 эти типы выбираются из небольшой группы заранее определенных возможных типов (целые числа, строки, даты, ...), для каждого из которых фиксированы размеры.Типичным примером является БД с данными о налогоплательщиках с большим количеством объектов, представляющих людей, описываемых фиксированными компонентами: ФИО (строка), дата рождения (дата), адрес (строка), зарплата (число) и еще несколько свойств.
Свойство (R3) исключает многие приложения, связанные с мультимедиа, CAD-CAM и обработкой изображений, в которых некоторые элементы данных, такие как битовые образы изображений, имеют сильно различающиеся и иногда очень большие размеры. Этому также мешает требование, чтобы отношения находились в "нормальной форме", налагаемое существующими коммерческими системами, из-за которого один объект не может ссылаться на другой. Это, конечно, очень сильное ограничение, если сравнить его с тем, что мы доказали раньше в дискуссиях этой книги.
Как только у нас есть некоторый объект, ссылающийся на другой объект, то ОО-модель обеспечивает простой доступ к непрямым свойствам этого объекта. Например, redblack.author.birth_year возвращает значение 1783, если переменная redblack присоединена к объекту слева на рис. 13.5. Реляционное описание неспособно представить поле со ссылкой author (автор), чьим значением является обозначение другого объекта.
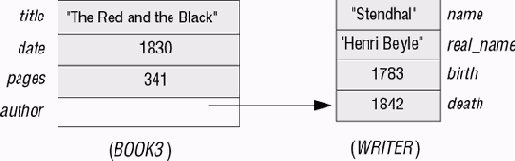
Рис. 13.5. Объект со ссылкой на другой объект
В реляционной модели имеется обходной путь для этой проблемы, но он тяжелый и непрактичный. Для представления описанной ситуации будут необходимы два отношения BOOKS и AUTHORS, введенные выше. Для их связывания можно выполнить уже показанную операцию соединения, использующую соответствие между полями author первого отношения и name - второго.
Для ответа на вопросы вида: "В каком году родился автор "Красного и черного"?" реляционная реализация должна будет вычислять соединения, проекции и т. п. В данном случае можно использовать указанное выше соединение, а затем взять его проекцию на атрибут birth.
Этот метод работает и широко используется, но он применим только для простых схем. Число операций соединения быстро возрастает в сложных случаях для систем, постоянно обрабатывающих запросы со многими связями, например: "Сколько комнат имеется в предыдущем доме менеджера отдела, из которого дама, закончившая на первом месте среднюю школу вместе с младшим дядей моей жены, была переведена, когда компания-учредитель провела второй тур реорганизации?" Для ОО-системы, поддерживающей во время выполнения сеть соответствующих объектов, ответ на этот запрос не представляет никакой сложности.
Наивные подходы
Мы можем исключить два крайних подхода к эволюции схем:
Отказ от ранее сохраненных объектов (революция схемы!). Разработчиков нового приложения эта идея может привлечь, так как облегчит им жизнь. Но пользователи этого приложения вряд ли будут в восторге.Переход к новому формату, требующий единовременного преобразования всех старых объектов. Хотя это решение может в ряде случаев подойти, оно не годится для большого хранилища объектов или для хранилища, которое должно быть постоянно доступно.На самом деле нам нужен способ трансформации объектов "на лету" в то время, когда они возвращаются или изменяются. Такое решение является наиболее общим, и далее мы будем рассматривать только его.
|
Если потребуется механизм одновременной трансформации многих объектов, то механизм "на лету" легко позволит это сделать: достаточно написать маленькую систему, которая возвращает все существующие объекты, используя новые классы, при необходимости применяет трансформацию на лету и все сохраняет. |
Неструктурированная информация
Последнее замечание о БД. Взрывной рост Интернета и появление средств поиска, основанного на контексте (в момент написания книги наиболее известными примерами таких средств были AltaVista, Web Crawler и Yahoo), показал, что можно получать доступ к данным и при отсутствии БД.
СУБД требуют, чтобы перед сохранением любых данных вы сначала конвертировали их в строго определенный формат схемы БД. Недавние исследования, тем не менее, показали, что 80% электронных данных в компаниях являются неструктурированными (т. е. располагаются вне БД, как правило, в текстовых файлах), несмотря на многолетнее использование баз данных. Сюда и внедряются средства поиска по контексту: по заданным пользователем критериям, включающим ключевые слова и фразы, они могут извлечь данные из неструктурированных или минимально структурированных документов. Почти каждый, кто испробовал эти средства, был ослеплен блеском скорости, с которой они извлекают информацию: секунды или двух достаточно, чтобы найти иголку в стоге байтов размером в тысячи гигабайт. Это неизбежно приводит к вопросу: нужны ли нам на самом деле структурированные БД?
Пока еще ответ - да. Неструктурированные и структурированные данные будут сосуществовать. Но БД больше не являются единственной выбором; все более и более изощренные средства для запросов смогут извлекать информацию, даже если она не имеет формата, требуемого БД. Разумеется, для создания таких средств лучше всего подходит ОО-технология.
Объектно-реляционное взаимодействие
Безусловно, сегодня наиболее общей формой СУБД является реляционная (relational) модель, базирующаяся на идеях, предложенных Коддом (E. F. Codd) в статье 1970 года.
Обсуждение: за пределами ОО-баз данных
Завершим этот обзор мечтами о возможных направлениях развития сохраняемости в будущем. Следующие далее наблюдения носят предварительный характер, их цель - побудить дальнейшие размышления, а не предложить конкретные ответы.
ОО-СУБД: примеры
Начиная с середины восьмидесятых появилось большое число продуктов с ОО-СУБД. Некоторыми из наиболее известных являются: Gemstone, Itasca, Matisse, Objectivity, ObjectStore, Ontos, O2, Poet, Versant. Недавно несколько компаний, таких как UniSQL, разработали объектно-реляционные системы, пытаясь объединить наилучшие черты обоих подходов. Главные производители реляционных СУБД также предлагают или анонсируют комбинированные решения, такие как Illustra фирмы Informix (частично базируется на проекте POSTGRES Калифорнийского университета в Беркли) и объявленная фирмой Oracle система Oracle 8.
Чтобы облегчить возможность взаимодействия, многие производители ОО-СУБД объединили свои силы в Object Database Management Group , которая предложила стандарт ODMG для унификации общего интерфейса ОО-БД и их языков запросов.
Давайте взглянем на две особенно интересные системы: Matisse и Versant.
Операции
Реляционной модели баз данных сопутствует реляционная алгебра, в которой определено много операций над отношениями. Три типичные операции - это выбор (selection), проекция (projection) и соединение (join).
Выбор выдает отношение, содержащее подмножество строк данного отношения, удовлетворяющее некоторому условию на значения полей. Применяя условие выбора "pages меньше, чем 400" к BOOKS, получим отношение, состоящее из первой, второй и последней строки BOOKS.
Проекция отношения на один или несколько атрибутов получается пропуском всех других полей и устранением повторяющихся строк в получившемся результате. Если спроектировать наше отношение на последний атрибут, то получим отношение с одним полем и с тремя кортежами: "STENDHAL", "FLAUBERT" и "BALZAC". Если же спроектировать его на три первых атрибута, то получится отношение с тремя полями, полученное из исходного вычеркиванием последнего столбца.
Соединение двух отношений это комбинированное отношение, полученное путем выбора атрибутов с согласованными типами в каждом из них и объединением строк с одинаковыми (в общем случае, согласованными) значениями этих атрибутов. Предположим, что у нас имеется еще отношение AUTHORS (АВТОРЫ):
| "BALZAC" | "Honore_ de Balzac" | 1799 | 1850 |
| "FLAUBERT" | "Gustave Flaubert" | 1821 | 1880 |
| "PROUST" | "Marcel Proust" | 1871 | 1922 |
| "STENDHAL" | "Henry Beyle" | 1783 | 1842 |
Тогда соединение отношений BOOKS и AUTHORS по согласованным атрибутам author и name будет следующим отношением:
| "The Red and the Black" | 1830 | 341 | "STENDHAL" | "Henry Beyle" | 1783 | 1842 |
| "The Charterhouse of Parma" | 1839 | 307 | "STENDHAL" | "Henry Beyle" | 1783 | 1842 |
| "Madame Bovary" | 1856 | 425 | "FLAUBERT" | "Gustave Flaubert" | 1821 | 1880 |
| "Euge_nie Grandet" | 1833 | 346 | "BALZAC" | "Honore_ de Balzac" | 1799 | 1850 |
Определения
Реляционная БД - это набор отношений (relations), каждое из которых состоит из множества кортежей (tuples) (или записей [records]). Отношения также называются таблицами, а кортежи строками, так как отношения удобно представлять в виде таблиц. Как пример, рассмотрим таблицу BOOKS (КНИГИ):
| "The Red and the Black" | 1830 | 341 | "STENDHAL" |
| "The Charterhouse of Parma" | 1839 | 307 | "STENDHAL" |
| "Madame Bovary" | 1856 | 425 | "FLAUBERT" |
| "Euge_nie Grandet" | 1833 | 346 | "BALZAC" |
Каждый кортеж состоит из нескольких полей (fields). У всех кортежей одного отношения одинаковое число и типы полей; в примере первое и последнее поля являются строками, а два других - целыми числами. Каждое поле идентифицируется именем: в примере с книгами это title, date и т. д. Имена полей (столбцов) называются атрибутами (attributes).
Реляционные базы обычно являются нормализованными, среди прочего это означает, что каждое поле имеет простое значение (целое число, вещественное число, строка, дата) и не может быть ссылкой на другой кортеж.
Основания ОО-баз данных
Становление ОО-БД подкреплялось тремя стимулами.
D1 Желанием предоставления разработчикам ОО-ПО механизма сохранения объектов, сопоставимого с их методом разработки и устраняющего сопротивление несогласованности.D2 Необходимостью преодоления концептуальных ограничений реляционных баз данных.D3 Возможностью предложения более развитых средств работы с базами данных, отсутствующих в ранних системах (реляционных и других), но сделавшихся возможными и необходимыми благодаря прогрессу технологии.Первый стимул наиболее очевиден для освоивших объектную разработку ПО, когда они сталкиваются с необходимостью сохранения объектов. Но он не обязательно является самым важным. Два других полностью относятся к области баз данных и не зависят от метода разработки.
Изучение понятия ОО-БД начнем с выявления ограничений реляционных систем D2 и того, чем они могут не устроить разработчиков ОО ПО (D1), а затем перейдем к новаторским достижениям движения за ОО-БД.
От сохраняемости к базам данных
Использование класса STORABLE становится недостаточным для приложений, полностью основанных на БД. Его ограниченность отмечалась уже выше: имеется лишь один входной объект, нет поддержки для запросов, основанных на содержимом, каждый вызов retrieved заново создает всю структуру, без всякого разделения объектов в промежутках между последовательными вызовами. Кроме того, в STORABLE не поддерживается одновременный доступ разных приложений клиента к одним и тем же сохраненным данным.
Хотя различные расширения этого механизма могут облегчить или устранить некоторые из этих проблем, полностью отработанное решение требует отдать предпочтение технологии баз данных.
Набор механизмов, ОО или нет, предназначенных для сохранения и извлечения элементов данных (в общем случае "объектов") заслуживает названия системы управления базой данных (СУБД), если он поддерживает следующие свойства:
Живучесть (Persistence): объекты могут пережить завершение отдельных сессий использующих их программ, а также сбои компьютера.Программируемая структура (Programmable structure): система рассматривает объекты как структурированные данные, связанные некоторыми точно определенными отношениями. Пользователи системы могут сгруппировать множество объектов в некоторую совокупность, называемую базой данных, и определить структуру конкретной БД.Произвольный размер (Arbitrary size): нет никаких заранее заданных ограничений (вытекающих, например, из размера основной памяти компьютера или ограниченности его адресного пространства) на число объектов в базе данных.Контроль доступа (Access control): пользователь может "владеть" объектами и определять права доступа к ним.Запросы, основанные на свойствах (Property-based querying): имеются механизмы, позволяющие пользователям и программам находить объекты в базе данных, задавая их абстрактные свойства, а не местоположение.Ограничения целостности (Integrity constraints): пользователи могут налагать некоторые семантические ограничения на объекты и заставлять базу данных поддерживать их выполнение.Администрирование (Administration): доступны средства для осуществления текущего контроля, аудита, архивации и реорганизации БД, добавления и удаления ее пользователей, распечатки отчетов.Разделение (Sharing): несколько пользователей или программ могут одновременно получать доступ к базе данных.Закрытие (Locking): пользователи или программы могут получать исключающий доступ (только для чтения, для чтения и записи) к одному или нескольким объектам.Транзакции (Transactions): можно так определять последовательности операций БД, называемые транзакциями, что либо вся транзакция будет выполнена нормально, либо при неудачном завершении не оставит никаких видимых изменений в состоянии БД.|
Стандартный пример транзакции - это перевод денег в банке с одного счета на другой, требующий двух операций - занесения в дебет первого счета и в кредит второго, которые должны либо обе успешно завершиться, либо вместе не выполниться. Если они завершаются неудачей, то всякое частичное изменение, такое как занесение в дебет первого счета, нужно отменить; это называется откатом (rolling back) транзакции. |
Приведенный список свойств не является исчерпывающим; он отражает то, что предлагается большинством коммерческих систем и ожидается пользователями.
Пороговая модель
Из предыдущих обсуждений можно вывести то, что может быть названо пороговой моделью ОО-БД: минимальное множество свойств, которым должна удовлетворять система БД, чтобы заслужить название ОО-БД (по работе [Zdonik 1990]). (Другие, также весьма желательные, свойства будут обсуждены ниже.) Имеется четыре требования, которым должна удовлетворять пороговая модель: база данных, инкапсуляция, идентифицируемость объектов и ссылки. Такая система должна:
T1 предоставлять все стандартные функции баз данных, перечисленные выше в этой лекции;T2 поддерживать инкапсуляцию, т. е. позволять скрытие внутренних свойств объектов и делать их доступными через официальный интерфейс;T3 связывать с каждым объектом его уникальный для данной базы идентификатор;T4 разрешать одним объектам содержать ссылки на другие объекты.Примечательно, что в этом списке отсутствуют некоторые ОО-механизмы, необходимые для этого метода, в частности наследование. Но это не так странно, как может показаться на первый взгляд. Все зависит от того, что мы ожидаем от БД. Система на пороговом уровне должна быть хорошей машиной ОО-БД, предоставляющей набор механизмов для сохранения, возвращения и обхода структур объектов, но оставляющей знания более высокого уровня о семантике этих объектов (например, отношения наследования) для уровня языка программирования или окружения разработки.
|
Опыт ранних систем ОО-БД подтверждает, что подход машины базы данных разумен. Некоторые из первых систем ударились в другую крайность и обзавелись полной "моделью данных" с соответствующим ОО-языком, поддерживающим наследование, родовыми классами, полиморфизм и т.п. Их производители обнаружили, что эти языки в конкуренции с языками ОО-разработки проигрывают (поскольку язык базы данных, как правило, менее общий и практичный, чем язык, который с самого начала проектировался как универсальный); тогда они стремглав побежали заменять свои собственные предложения интерфейсами с основными ОО-языками. |
Преобразование объектов на лету
Механика преобразования на лету может оказаться весьма мудреной: мы должны быть очень внимательны, чтобы не получить в результате испорченные объекты или БД.
Во-первых, у приложения может не оказаться права изменять запомненный объект из-за существования разных версий породившего его класса. Это вполне разумно, поскольку другие приложения могут все еще использовать старую версию этого объекта. Проблема эта не нова для баз данных. Можно сделать так, чтобы используемый приложением объект был совместим с описанием собственного класса; механизм преобразования на лету обеспечит выполнение этого свойства. Заносить ли преобразованный объект обратно - это отдельный вопрос, классический вопрос привилегированного доступа, возникающий всякий раз, когда несколько приложений или несколько сессий одного и того же приложения получают доступ к сохранению данных. Различные его решения предлагаются базами данных, обычными и ОО.
Независимо от ответа на вопрос о сохранении после изменения более новая и трудная проблема состоит в том, что каждое приложение должно делать с устаревшими объектами. Эволюция схемы включает три отдельных аспекта - выявление, извещение и исправление:
выявление (Detection) - обнаружение рассогласований объекта (восстанавливаемый объект устарел);извещение (Notification) - уведомление системы о рассогласовании объекта, чтобы она смогла соответствующим образом на это прореагировать, а не продолжала работать с неправильным объектом (вероятная причина главной неприятности в будущем!);исправление (Correction) - приведение рассогласованного объекта в согласованное состояние, т. е. по превращению его в корректный экземпляр новой версии своего класса - гражданина или по крайней мере постоянного резидента системы.Все три задачи являются весьма тонкими. К счастью, их можно решать по отдельности.
Сохранение и извлечение структур объектов
Как только появляются составные объекты, простое запоминание и извлечение индивидуальных объектов становится недостаточным, поскольку в них могут находиться ссылки на другие объекты, а объект, лишенный своих связников (см. лекциию 8 курса "Основы объектно-ориентированного программирования"), некорректен. Это наблюдение привело нас в лекции 8 курса "Основы объектно-ориентированного программирования" к принципу Замыкания Сохраняемости, утверждающему, что всякий механизм сохранения и возвращения должен обрабатывать вместе с некоторым объектом всех его прямых и непрямых связников, что показано на рис. 13.1.

Рис. 13.1. Необходимость в замыкании при сохранении
Принцип Замыкания Сохраняемости утверждает, что всякий механизм, сохраняющий O1, должен также сохранить все объекты, на которые он непосредственно или опосредованно ссылается, иначе при извлечении этой структуры можно получить бессмысленное значение ("висящую ссылку") в поле loved_one объекта O1.
Мы рассмотрели механизмы класса STORABLE, предоставляющие соответствующие средства: store для сохранения структуры объекта и retrieved для ее извлечения. Это ценный механизм, чье присутствие в ОО-окружении само по себе является большим преимуществом перед традиционными окружениями. В лекции 8 курса "Основы объектно-ориентированного программирования" приведен типичный пример его использования: реализация команды редактора SAVE. Вот еще один пример из практики нашей фирмы ISE. Наш компилятор выполняет несколько проходов по представлениям текста программы. Первый проход создает внутреннее представление, называемое Деревом Абстрактного Синтаксиса (Abstract Syntax Tree (AST)). Задача последующих проходов заключается в постепенном добавлении семантической информации в AST ("украшении дерева") до тех пор, пока ее не станет достаточно для генерации целевого кода компилятором. Каждый проход завершается операцией store; а следующий проход начинается восстановлением AST с помощью операции retrieved.
Механизм STORABLE работает не только на файлах, но и на сетевых соединениях таких, как сокеты; он на самом деле лежит в основе библиотеки клиент-сервер Net.
Сохраняемость средствами языка
Для удовлетворения многих потребностей в сохраняемости достаточно иметь связанный с окружением разработки набор механизмов для записи объектов в файлах и их чтения. Для простых объектов, таких как числа или символы, можно использовать средства ввода-вывода, аналогичные средствам традиционного программирования.
У13.1 Динамическая эволюция схем
Предложите, как расширить методы эволюции схем, развитые в этой лекции, чтобы учесть случай, при котором классы программной системы могут изменяться во время выполнения системы.
У13.2 Объектно-ориентированные запросы
Обсудите, в каком виде могут формулироваться запросы в ОО-БД.
 |
|
|
Versant
Versant от фирмы Versant Object Technology - это ОО-СУБД, работающая с C++, Smalltalk и нотацией данной книги. Ее модель данных и язык интерфейса поддерживают многие из основных концепций ОО-разработки, в частности классы, множественное наследование, переопределение компонентов, переименование компонентов, полиморфизм и универсальность.
Versant - это одна из СУБД, отвечающих стандарту ODMG. Она предназначена для архитектуры клиент-сервер и, как и Matisse, допускает кэширование недавно использованной информации на уровне страниц на стороне сервера и на уровне объектов на стороне клиента.
При разработке Versant особое внимание было уделено блокировке и транзакциям. В ней можно блокировать отдельные объекты. Приложение может запросить чтение, обновление или запись заблокированного объекта. Обновления служат для устранения взаимных блокировок: если вам нужно прочесть заблокированный объект и записать в него, то требуется вначале запросить право на его обновление, предоставляемое при условии, что никакой другой клиент им в данный момент не пользуется. При этом остальные клиенты могут читать объект, пока не начнется (гарантированное) выполнение вашего запроса на запись. Непосредственный переход от чтения заблокированного объекта к записи мог бы привести к взаимной блокировке: каждый из двух клиентов мог бы ждать до бесконечности, пока другой не снимет свою блокировку.
Механизм транзакций обеспечивает как короткие, так и длинные транзакции; приложение может оставить объект на любое время. Поддерживаются версии объектов и оптимистическая блокировка.
Механизм запросов позволяет запросить все экземпляры класса, включая и экземпляры его собственных потомков. Как уже отмечалось, это позволяет добавлять новый класс без переопределения запросов, применимых к его ранее определенным предкам.
Другой особенностью Versant является ее механизм, позволяющий сообщать приложению о различных событиях в БД, например, об удалении или обновлении объекта. Получив такое извещение, приложение может выполнить предусмотренные на этот случай действия.
СУБД Versant предоставляет пользователям богатый набор типов данных, включая и множество заранее определенных коллекций классов. Это позволяет проводить эволюцию схемы при условии, что новые поля инициализируются предопределенными значениями. В ней также имеются возможности индексации, используемые в механизме запросов.
Версии классов и эволюция схемы
Объекты - это не единственные элементы, для которых требуется поддержка версий: со временем могут изменяться и порождающие их классы. Это проблема эволюции схемы, которая обсуждалась в начале этой лекции. Только очень немногие ОО-СУБД полностью поддерживают эволюцию схем.
Версии объекта
Так называется способность запоминать предыдущие состояния объекта после, того, как вызовы процедур его изменили. Это особенно важно в случае параллельного доступа. Предположим, что объект O1 содержит ссылку на объект O2. Клиент изменяет некоторые поля O1, отличные от этой ссылки. Другой клиент изменяет O2. Тогда, если первый клиент попытается проследовать по ссылке, он может обнаружить версию O2, несовместную с O1.
Некоторые ОО-СУБД справляются с этой проблемой, трактуя каждую модификацию объекта как создание нового объекта, тем самым, поддерживая доступ к старым версиям объектов.
Вне рамок замыкания сохраняемости
Принцип Замыкания Сохраняемости теоретически применим ко всем видам сохранения. Как мы видели, это позволяет сохранить совместность сохраненных и восстановленных объектов.
Но в некоторых практических ситуациях требуется немного изменить структуру данных перед тем, как к ней будут применены такие механизмы, как STORABLE или средства ОО-баз данных, рассматриваемые далее в этой лекции. Иначе можно получить больше, чем хотелось бы.
Такая проблема возникает, в частности, из-за разделяемых структур, как в следующем примере.
Требуется заархивировать сравнительно небольшую структуру данных. Так как она содержит одну или более ссылок на большую разделяемую структуру, то принцип замыкания сохраняемости требует архивирования и этой структуры. В ряде случаев этого делать не хочется. Например, как показано на рис. 13.1, объект личность может через поле address ссылаться на гораздо большее множество объектов, представляющих географическую информацию. Аналогичная ситуация возникает в продукте ArchiText фирмы ISE, позволяющем пользователям манипулировать структурами таких документов, как программы или спецификации. Каждый документ, подобно структуре FAMILY на рис. 13.2, содержит ссылку на структуру, представляющую основную грамматику, играющую ту же роль, что и структура CITY для FAMILY. Мы хотели бы сохранять документ, а не грамматику, которая уже где-то имеется и которую разделяют многие документы.
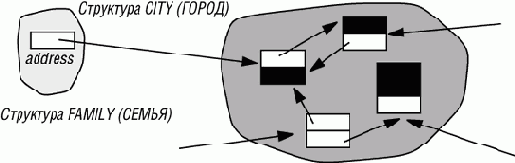
Рис. 13.2. Малая структура, ссылающаяся на большую разделяемую структуру
В таких случаях хочется "оборвать" ссылки на разделяемые структуры перед сохранением ссылающейся структуры. Однако это тонкая процедура. Во-первых, нужно, как всегда, быть уверенным, что в момент новой загрузки объекты останутся совместными - будут удовлетворять своим инвариантам. Но здесь есть и практическая проблема: как обойтись без усложнений и ошибок? На самом деле, не хотелось бы менять исходную структуру, ссылки нужно оборвать только в сохраняемой версии.
И вновь методы построения ОО-ПО дают элегантное решение проблемы, основанное на идеях классов поведения, рассмотренных при обсуждении наследования.
Одна из версий процедуры сохранения custom_independent_store работала так же, как и предопределенная процедура independent_store. Но она позволяла также каждому потомку библиотечного класса ACTIONABLE переопределять ряд процедур, которые по умолчанию ничего не делали, например, процедуры pre_store и post_store, выполняющиеся непосредственно перед и после сохранения объекта. Таким образом, можно, чтобы pre_store выполняла:
preserve; address := Void,где preserve - это тоже компонент ACTIONABLE, который куда-нибудь безопасно копирует объект. Тогда post_action будет выполнять вызов:
restore,восстанавливающий объект из сохраненной копии.
В общем случае того же эффекта можно добиться с помощью вызова вида:
store_ignore ("address"),где store_ignore получает в качестве аргумента имя поля. Так как реализация store_ignore может просто пропускать поле, устраняя необходимость двустороннего копирования посредством preserve и restore, то в данном случае это будет более эффективно, но механизм pre_store-post_store является общим, позволяя выполнять необходимые действия до и после сохранения. Разумеется, нужно убедиться в том, что эти действия не будут неблагоприятно влиять на объекты.
Аналогично можно справиться и с проблемой несовместности во время возвращения, для этого достаточно переопределить процедуру post_retrieve, выполняемую непосредственно перед тем, как восстанавливаемый объект присоединится к сообществу уже одобренных объектов. Например, приложение может переопределить post_retrieve в нужном классе-наследнике ACTIONABLE, чтобы она работала так:
address := my_city_structure.address_value (...)тем самым снова делая объект представительным, еще до того, как он сможет нарушить инвариант своего класса или какое-нибудь неформальное ограничение.
Конечно, нужно соблюдать некоторые правила, связанные с механизмом класса ACTIONABLE; в частности, pre_store не должна вносить в структуры данных никаких изменений, которые не были бы сразу же исправлены процедурой post_store.Нужно также обеспечить, чтобы post_retrieve выполняла необходимые действия (часто те же, что и post_store) для корректировки всех несовместностей, внесенных в сохраненные данные процедурой pre_store. Предложенный механизм, используемый с соблюдением указанных правил, позволит вам остаться верным духу принципа Замыкания Сохраняемости, делая его применение более гибким.
Выявление
Мы определим две общих категории политики выявления: номинальную (nominal) и структурную (structural).
В обоих случаях задача состоит в выявлении рассогласования между двумя версиями породившего объект класса, существующих в сохраняющей и возвращающей системах.
При номинальном подходе каждая версия класса идентифицируется именем. Это предполагает наличие специального механизма регистрации, который может иметь два варианта:
При использовании системы управления конфигурацией можно регистрировать каждую новую версию класса и получать в ответ имя этой версии (или самому задавать это имя).Возможна и автоматическая схема, аналогичная возможности автоматической идентификации в OLE 2 фирмы Майкрософт или методам, используемым для присвоения "динамических IP-адресов" компьютерам в Интернете. Эти методы основаны на присвоении случайных номеров, достаточно больших для того, чтобы сделать вероятность совпадения бесконечно малой.Для каждого из этих решений требуется некоторый централизованный регистр. Если вы хотите избежать связанных с этим трудностей, то используйте структурный подход. Его идея в том, что каждая версия класса имеет свой дескриптор, строящийся по текущей структуре, заданной в объявлении класса. Механизм сохранения объектов должен сохранять дескрипторы их классов. (Конечно, при сохранении многих экземпляров одного класса достаточно запомнить только одну копию его дескриптора.) После этого механизм выявления рассогласований прост: достаточно сравнить дескриптор класса каждого сохраненного объекта с новым дескриптором этого класса. Если они различны, то имеется рассогласованный объект.
Что входит в дескриптор класса? Ответ связан с соотношением между эффективностью и надежностью. Из соображений эффективности не хотелось бы тратить много места на информацию о классе или чересчур много времени на сравнение дескрипторов во время возвращения, но надежность требует минимизации риска пропуска рассогласования. Вот несколько возможных стратегий:
C1 Одна крайность состоит в том, чтобы в качестве дескриптора класса взять его имя.В общем случае этого недостаточно: если имя класса, породившего объект, в сохранившей его системе совпадет с именем класса в системе, возвратившей этот объект, то объект будет принят, даже если эти два класса совершенно несовместимы. Неизбежно последуют неприятности.C2 Другая крайность - использовать в качестве дескриптора класса весь его текст, не обязательно в виде строки, но в некоторой подходящей внутренней форме (дерева абстрактного синтаксиса). Понятно, что с точки зрения эффективности это самое плохое решение: и занимаемая память, и время сравнения дескрипторов максимальны. Но оно может оказаться неудачным и с точки зрения надежности, так как некоторые изменения класса являются безвредными. Предположим, например, что к тексту класса добавилась новая процедура, но атрибуты класса и его инвариант не изменились. Тогда нет ничего плохого в том, чтобы рассматривать возвращаемый объект как соответствующий современным требованиям, а определение его как рассогласованного может привести к неоправданным затруднениям (таким как исключение) в возвращающей системе.C3 Более реалистичный подход состоит в том, чтобы включить в дескриптор класса его имя и список имен атрибутов и их типов. По сравнению с номинальным подходом остается риск того, что два совершенно разных класса могут иметь одинаковые имена и атрибуты, но (в отличие от С1) такие случайные совпадения на практике чрезвычайно маловероятны.C4 Еще один вариант C3 включает не только список атрибутов, но и инвариант класса. Это приведет к тому, что добавление или удаление подпрограммы, не приводящей к рассогласованию объекта, окажется безвредным, так как, если бы изменилась семантика класса, то изменился бы и его инвариант.C3 - это минимальная разумная политика, и в обычных случаях она представляется хорошим выбором, по крайней мере для начала.
Запросы
Реляционная модель допускает запросы - одно из главных требований к базе данных в нашем списке - в стандартизированном языке, называемом SQL. Они используются в двух формах: одна применяется непосредственно людьми, а другая ("встроенный SQL") используется в программах. В первой форме типичный SQL-запрос выглядит так:
select title, date, pages from BOOKSОн выдает названия, даты и число страниц для всех книг из таблицы BOOKS. Как мы видели, этот запрос в реляционной алгебре является операцией проекции. Другой пример:
select title, date, pages, author where pages < 400соответствует в реляционной алгебре выбору. Запрос:
select title, date, pages, author, real_name, birth, date from AUTHORS, BOOKS where author = nameэто внутреннее соединение, дающее тот же результат, что и приведенный пример соединения.
Как было подчеркнуто выше, СУБД поддерживают запросы. Здесь ОО-системы в случае эволюции схем могут оказаться более гибкими, чем реляционные. Изменение схемы реляционной БД часто означает необходимость изменения текстов запросов и их перекомпиляцию. В ОО-БД запросы формулируются относительно объектов; вы спрашиваете о некоторых компонентах экземпляров некоторого класса. Здесь в качестве экземпляров могут выступать как прямые экземпляры данного класса, так и экземпляры его собственных потомков. Поэтому, если у класса, для которого сформулирован запрос, появляется новый потомок, то данный запрос применим и к экземплярам этого нового класса и позволяет извлекать из них требуемую информацию.
Базисная схема
Контексты, события и команды образуют базисные ингредиенты для определения основной операции интерактивного приложения, поддерживаемой конструктором приложений: разработчик приложения будет перебирать интересующие его пары вида контекст-событие (какие события распознаются в каких контекстах) и для каждой из них определять связанную с ней команду.
Эта важная идея может быть реализована как первая версия конструктора приложений. У него должны быть каталоги контекстов и событий (базирующиеся на имеющихся инструментальных средствах), а также каталог команд (предоставленный окружением разработки и допускающий расширение разработчиками приложений). Графическая метафора должна позволить выбрать нужную комбинацию контекст-событие, например, щелчок левой кнопкой мыши на некоторой кнопке, и команду, которая будет выполняться в ответ на эту комбинацию.
Библиотека и конструктор приложений
Чтобы удовлетворить нужды разработчиков и дать им возможность создавать приложения, устраивающие их конечных пользователей, требуется пойти дальше инструментария. Разработчикам необходимо предоставить переносимые средства высокого уровня, освобождающие их от утомительной и регулярно повторяющейся работы, позволив им посвятить свое творчество действительно новаторским аспектам.
Наборы инструментов содержат много необходимых механизмов и дают хорошую основу. Остается скрыть лишние детали и пополнить их полезными средствами.
В основе предлагаемого решения лежит библиотека повторно используемых классов. Эти классы поддерживают основные абстракции данных, отвечающие понятиям: окно, меню, контекст, событие, команда, состояние, приложение.
Для решения некоторых задач, встречающихся при создании приложения, разработчикам было бы удобней не писать, как обычно, тексты программ, но использовать интерактивную систему, называемую конструктором приложений. Такая система позволяет им выражать свои потребности в графическом, WYSIWIG виде; иными словами, использовать в их собственной работе стиль интерфейса, который они предлагают своим пользователям. Конструктор приложений - это инструмент, чьими конечными пользователями являются сами разработчики, они используют конструктор приложений для создания тех частей своих систем, которые могут быть заданы визуально и интерактивно. Термин "конструктор приложений" показывает, что это средство гораздо более амбициозное, чем простой "конструктор интерфейса", позволяющий создавать только интерфейс приложения. Конструктор приложения должен идти дальше в представлении структуры и семантики приложения, останавливаясь только в том случае, когда для решения некоторой подзадачи необходимо написать некоторый программный код.
При определении библиотеки и конструктора приложений, как всегда, будем руководствоваться критериями повторного использования и расширяемости. В частности, это означает, что для каждой описываемой ниже абстракции данных (такой, как контекст, команда или состояние) конструктор приложения должен предоставить два средства:
для повторного использования - каталог (событий, контекстов, состояний и т. д.), содержащий заранее определенные образцы данной абстракции, которые могут быть непосредственно включены в приложение;для расширяемости - редактор (контекстов, команд, состояний и т. д.), позволяющий разработчикам создавать собственные варианты либо с самого начала, либо, выбрав некоторый элемент из каталога и изменив его нужным образом.Фигуры (изображения)
Прежде всего нам нужно подходящее множество абстракций для графической части интерактивного приложения. Для простоты мы будем рассматривать только двухмерную графику.
Прекрасную модель представляют географические карты. Карта (страны, области, города) дает визуальное представление некоторой реальности. Проектирование карты использует несколько уровней абстракции:
Мы должны видеть реальность, стоящую за моделью (в почти абстрактном виде), как множество геометрических форм или фигур. На карте эти фигуры представляют реки, дороги, города и другие географические объекты.Карта описывает некоторое множество фигур, называемое миром.Карта показывает только часть мира - одну или более областей, называемых окнами. Окна имеют прямоугольную форму. Например, у карты может быть одно главное окно, посвященное стране, и вспомогательные окна, посвященные большим городам или удаленным частям (например, Корсике на картах Франции или Гавайям на картах США).Физически карта появляется на физическом носителе изображения, устройстве. Этим устройством обычно является лист бумаги, но им может быть и экран компьютера. Различные части устройства будут предназначены для разных окон.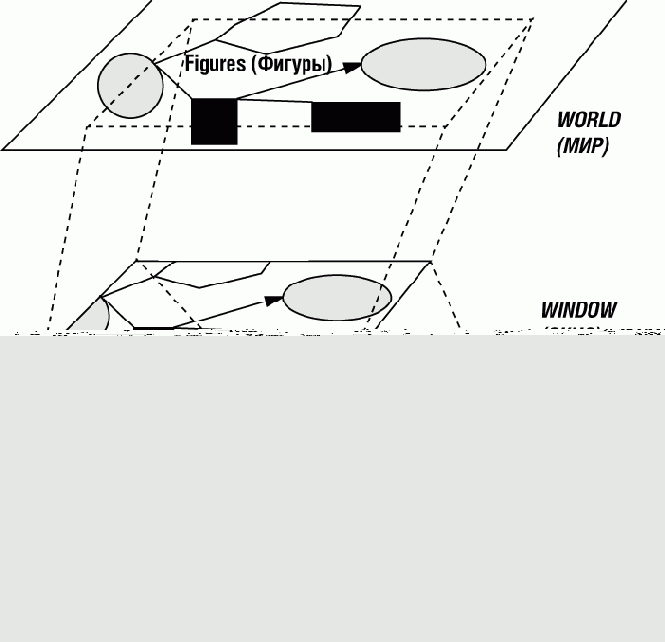
Рис. 14.2. Графические абстракции
Четыре базовых понятия - WORLD, FIGURE, WINDOW, DEVICE - легко переносятся на общие графические приложения, в которых мир может содержать произвольные фигуры, представляющие интерес для некоторого компьютерного приложения, а не только представления географических объектов. Прямоугольные области мира (окна) будут изображаться на прямоугольных областях устройства (экрана компьютера).
На рис. 14.2 показаны три плоскости: мир (вверху), окно (посредине) и устройство (внизу). Понятие окна играет центральную роль, поскольку каждое окно связано как с некоторой областью мира, так и с некоторой областью устройства. С окнами также связано единственное существенное расширение базовых понятий - поддержка иерархически вложенных окон. У наших окон могут быть подокна (без всяких ограничений на уровень вложенности). (На рисунке вложенных окон нет.)
Графические абстракции
Многие приложения используют графические изображения для представления объектов внешней системы. Рассмотрим простое множество абстракций, покрывающее эти потребности.
Графические классы и операции
Все классы, представляющие фигуры, являются наследниками отложенного класса FIGURE, среди стандартных компонентов которого имеются display (показать), hide (скрыть), translate (сдвинуть), rotate (повернуть), scale (масштабировать).
Безусловно, множество фигур должно быть расширяемым, позволяя разработчикам приложений (и, опосредованно, конечным пользователям графических средств) определять их новые типы. Мы уже видели, как это можно сделать: предоставить класс COMPOSITE_FIGURE, построенный с помощью множественного наследования из класса FIGURE и такого типа контейнера, как LIST [FIGURE].
Графические системы, оконные системы, инструментальные средства
Многие вычислительные платформы предлагают средства для построения графических интерактивных приложений. Для реализации графики имеются соответствующие библиотеки такие, как GKS и PHIGS. Что касается интерфейса пользователя, то базовые оконные системы (такие, как Windows API, Xlib API под Unix'ом и Presentation Manager API под OS/2) имеют чересчур низкий уровень, чтобы ими было удобно пользоваться разработчикам приложений, но они дополняются "инструментариями", например, основанными на протоколе интерфейса пользователя Motif.
Все эти системы, удовлетворяя определенным потребностям, недостаточны для выполнения всех требований разработчиков. Перечислим некоторые ограничения.
Их трудно использовать. Чтобы освоить инструментальные средства, основанные на протоколе Motif, разработчики должны изучить многотомную документацию, описывающую сотни встроенных функций на Си и структур, носящих такие внушающие благоговейный ужас имена как XmPushButtonCallbackStruct , где в Button буква B большая, а в back - b малая. К трудностям и небезопасности C добавляется сложность инструментария. Использование базового интерфейса программирования приложений API в Windows также утомительно.Хотя предлагаемый инструментарий включает объекты пользовательского интерфейса - кнопки, меню и т. п., - у некоторых из них хромает графика (геометрические фигуры и их преобразования). Для добавления в интерфейс настоящей графики требуются значительные усилия.Различные инструментальные средства несовместимы друг с другом. Графика Motif, Windows и Presentation Manager, основанная на похожих понятиях, имеет множество различий. Некоторые из них существенны. Так, в Windows и PM создаваемый объект интерфейса сразу же выводится на экран, а в Motif сначала строится соответствующая структура, а затем вызов операции "реализовать" ее показывает. Некоторые различия связаны с разными соглашениями (координаты экрана откладываются от верхнего левого угла в PM и от нижнего левого угла у других). Многие соглашения об интерфейсах пользователя также различны. Большинство этих различий доставляет неприятности конечным пользователям, желающим иметь нечто работающее и "приятно выглядящее" и которым неважно, какие углы у окна - острые или слегка закругленные. Эти различия еще больше неприятны разработчикам, которые должны выбирать между потерей части их потенциального рынка и тратой драгоценного времени на усилия по переносу.Команды
Выделение команд как важной абстракции является ключевым шагом в разработке хороших интерактивных приложений.
Это понятие было изучено в лекции 3 в качестве учебного примера для операции отката Undo. Напомним, что объект команда содержит информацию, необходимую для выполнения запрошенной пользователем операции и, если поддерживается Undo, то и для отмены ее действия.
К обсужденным выше компонентам добавим еще атрибут exit_label, объясняемый ниже.
Конечные пользователи, разработчики приложений и разработчики инструментальных средств
Для устранения непонимания начнем с терминологии. Слово "пользователь" (одно из самых оскорбительных для компьютерщиков) здесь может ввести в заблуждение. Некоторые люди, называемые разработчиками приложений, создают интерактивные приложения, используемые другими людьми, называемыми конечными пользователями. Разработчики приложений, в свою очередь, рассчитывают на графические средства, созданные третьей группой - разработчиками инструментальных средств. Существование этих трех категорий объясняет, почему слово "пользователь" без дальнейшего уточнения неоднозначно: конечные пользователи являются пользователями разработчиков приложений, но сами разработчики приложений являются пользователями разработчиков инструментальных средств.
Приложение - это интерактивная система, созданная разработчиком. Конечный пользователь начинает сессию и исследует возможности системы, задавая ей различные входы. Сессии для приложений, что объекты для классов: индивидуальные экземпляры общего образца.
Проанализируем потребности разработчиков, желающих предоставить своим конечным пользователям полезные приложения с графическим интерфейсом.
Контекст-Событие-Команда-Состояние: резюме
Определенные только что абстракции могут послужить основой для мощного конструктора интерактивных приложений, представляющего не только конструктора интерфейса, но средство, позволяющее разработчикам графически конструировать приложение; они будут использовать визуальные каталоги контекстов, событий и, что наиболее важно, команд, графически выбирать из них нужные элементы, будут устанавливать связи вида контекст-событие-команда с помощью простого механизма перетаскивания до тех пор, пока не получат полное приложение.
Так как простые приложения часто имеют лишь одно состояние, то наш конструктор приложений постарается сделать понятие состояния незаметным. Для более сложных приложений разработчики смогут использовать столько состояний, сколько потребуется, и последовательно получать новое состояние из уже имеющегося.
Контексты и объекты интерфейса пользователя
Инструментальные средства GUI предлагают множество готовых "Объектов интерфейса пользователя": окна, меню, кнопки, панели. Вот пример кнопки OK.

Рис. 14.3. Кнопка ОК
По внешнему виду объект интерфейса пользователя - это просто некоторая фигура. Но в отличие от фигур, рассмотренных ранее, он, как правило, не имеет никакого отношения к окружающему миру: его роль ограничивается обработкой входа от пользователя. Точнее говоря, объект интерфейса пользователя представляет специальный случай контекста.
Для понимания необходимости контекста, заметим, что по одному событию в общем случае невозможно определить правильный ответ ПО. Например, нажатие кнопки мыши дает разные результаты в зависимости от того, где находится курсор мыши. Контекст - это условия, полностью определяющие отклик приложения на появление события.
Тогда в общем случае контекст - это просто логическое значение, т. е. значение, которое будет истинно или ложно в каждый момент выполнения ПО.
Наиболее общие контексты связаны с объектами интерфейса пользователя. Показанная выше кнопка задает логическое условие-контекст "курсор мыши на кнопке (внутри)?" Контексты такого рода будут записываться в виде IN (uio), где uio - это объект интерфейса пользователя.
Для каждого контекста c его отрицание not c также является контекстом; not IN (uio) называется также OUT (uio). Контекст ANYWHERE всегда истинен, а его отрицание NOWHERE всегда ложно.
У нашего конструктора приложений будет каталог контекстов, в который будут входить ANYWHERE и контексты вида IN(uio) для всех объектов интерфейса пользователя uio. Кроме того, хочется предоставить разработчикам приложений возможность определять собственные контексты, для этой цели конструктор приложений предоставит специальный редактор. Среди прочего, этот редактор позволит получать контекст not c по любому c (в частности, и по c из каталога).
Координаты
Нам нужны две системы координат: координаты устройства и мировые координаты. Координаты устройства задают положения элементов, изображаемых на этом устройстве. На экранах компьютеров они часто измеряются в пикселах; пиксел (элемент изображения) - это размер маленькой точки, обычно самого малого из изображаемых элементов.
Стандартной единицы для мировых координат нет и быть не может - систему мировых координат лучше оставить разработчикам: астрономы могут пожелать работать со световыми годами, картографы - с километрами, биологи - с миллиметрами или микронами.
Так как окно отражает часть мира, то у него есть некоторое местоположение (определяемое мировыми координатами x и y его верхнего левого угла) и некоторые размеры (длина по горизонтали и вертикали соответствующей части мира). Местоположение и размеры выражаются в единицах мировых координат.
Так как окно изображается на части устройства, то у него имеется некоторое местоположение на устройстве (определяемое координатами x и y его верхнего левого угла на устройстве) и некоторые размеры на устройстве, все выражаемые в единицах координат устройства. Для окна, не имеющего родителя, местоположение определяется по отношению к устройству, а для подокна местоположение определяется по отношению к его родителю. Благодаря этому соглашению всякое приложение, использующие окна, может выполняться как внутри всего экрана, так и в предварительно размещенном окне.
Математическая модель
Некоторые из неформально представленных в этой лекции понятий, в частности понятие состояния, имеют элегантное математическое описание, основанное на понятии конечной функции и математическом преобразовании, известном как карринг (currying).
Поскольку эти результаты не используются в остальной части книги и представляют интерес в основном для читателей, которым нравится исследовать математические модели понятий, связанных с ПО, то соответствующие разделы вынесены на компакт-диск, сопровождающий эту книгу, в виде отдельной главы, названной "Математические основы"1), взятой из [M 1995e].
Механизмы взаимодействия
Обратим теперь внимание на то, как наши приложения будут взаимодействовать с пользователями.
Необходимые средства
Какие средства нужны для создания полезных и приятных интерактивных приложений?
Обработка событий
Теперь у нас есть список событий и список контекстов, для которых эти события могут быть значимы. Ответы будут включать команды и метки переходов.
Операции над окнами
Принимая во внимание иерархическую природу окон, мы сделаем класс WINDOW наследником класса TWO_WAY_TREE, реализующего деревья. В результате все иерархические операции легко доступны как операции на деревьях: добавить подокно (вершину-ребенка), переподчинить другому окружающему окну (другому родителю) и т. д. Для задания положения окна в мире и в устройстве будем использовать следующие процедуры (все с двумя аргументами):
| Положение в мире | go | pan |
| Положение на устройстве | place_proportional place_pixel | move_proportional move_pixel |
Процедуры _proportional интерпретируют значения своих аргументов как отношение высоты и ширины окна родителя, а аргументами остальных процедур являются абсолютные значения (в мировых координатах для go и pan, и в координатах устройства для процедур _pixel). Имеются аналогичные процедуры и для задания размеров окна.
Переносимость и адаптация к платформе
Некоторые разработчики приложений предпочитают переносимые библиотеки, позволяющие написать один исходный текст системы. Для переноса системы на другую платформу достаточно ее перекомпилировать, не внося никаких изменений. Другие хотели бы обратного: получить полный доступ ко всем специфическим элементам управления и прочим "штучкам" конкретной платформы, например, Microsoft Windows, но в удобном виде (а не на низком уровне стандартных библиотек). Третьи хотели бы понемногу и того и другого: переносимости по умолчанию и возможности, если потребуется, стать "родным" для данной платформы.
При аккуратном проектировании, основанном на двухуровневой структуре, можно попытаться удовлетворить все три группы:

Рис. 14.1. Архитектура графической библиотеки
Для конкретизации на рисунке приведены имена соответствующих компонентов из окружения ISE, но идея применима к любой графической библиотеке. На верхнем уровне (Vision) находится переносимая графическая библиотека, а на нижнем уровне - специализированные библиотеки, такие как WEL для Windows, каждая из них приспособлена к "своей" платформе.
WEL и другие библиотеки нижнего уровня можно использовать непосредственно, но они также служат как зависящие от платформы компоненты верхнего уровня: механизмы Vision реализованы посредством WEL для Windows, посредством MEL для Motif и т. д. У такого подхода несколько преимуществ. Разработчикам приложений он дает надежду на совместимость понятий и методов. Разработчиков инструментальных средств он избавляет от ненужного дублирования и облегчает реализацию высокого уровня, базирующуюся не на прямом всегда опасном интерфейсе с C, а на ОО-библиотеках, снабженных утверждениями и наследованием, таких как WEL. Связь между этими двумя уровнями основана на описателях (см. лекцию 6).
У разработчиков приложений имеется выбор:
Для обеспечения переносимости следует использовать верхний уровень. Он также представляет интерес для разработчиков, которые, даже работая для одной платформы, хотят выиграть от более высокой степени абстракций, предоставляемых такими библиотеками высокого уровня, как Vision.Для получения прямого доступа ко всем специфическим механизмам некоторой платформы (например, многочисленным элементам управления, предоставляемым Windows NT), следует перейти на соответствующую библиотеку нижнего уровня.Рассмотрим один тонкий вопрос.
Как много специфических для данной платформы возможностей допустимо потерять при использовании переносимой библиотеки? Корректный ответ на него является результатом компромисса. Некоторые из первых переносимых библиотек использовали подход пересечения ("наименьшего общего знаменателя"), ограничивающий предлагаемые возможности теми, которые предоставляются всеми поддерживаемыми платформами. Как правило, этого недостаточно. Авторы библиотек могли использовать и противоположный подход - объединения: предоставить каждый из механизмов каждой из поддерживаемых платформ, используя точные алгоритмы для моделирования механизмов, первоначально отсутствующих на той или иной платформе. Такая политика приведет к огромной и избыточной библиотеке. Правильный ответ находится где-то посередине: для каждого механизма, присутствующего не на всех платформах, авторы библиотеки должны отдельно решать, достаточно ли он важен для того, чтобы промоделировать его на всех платформах. Результатом должна явиться согласованная библиотека, достаточно простая, чтобы использоваться без знаний особенностей отдельных платформ, и достаточно мощная для создания впечатляющих графических приложений.
Для разработчиков приложений еще одним критерием в выборе между двумя уровнями служит эффективность. Если основной причиной выбора верхнего уровня служит абстрактность, а не переносимость, то можете быть уверены - включение дополнительных классов приведет к потерям в памяти. Для правильно спроектированных библиотек потерями времени можно обычно пренебречь. Поэтому эффективность по памяти определяет, нужно ли это делать. Ясно, что библиотека для одной платформы (например, WEL) будет более компактной.
Наконец, заметим, что оба решения не являются полностью взаимоисключающими. Можно сделать основную часть работы на верхнем уровне, а затем добавить "бантики" для пользователей, работающих с библиотекой для самой продаваемой платформы. Конечно, это следует делать аккуратно, беззаботное смешение переносимых и непереносимых элементов быстро ликвидирует любую ожидаемую выгоду от переносимой разработки.
Один элегантный образец проекта (используемый ISE в некоторых своих библиотеках) основан на попытке присваивания (см. лекцию 16 курса "Основы объектно-ориентированного программирования"). Его идея в следующем. Рассмотрим некоторый графический объект, известный через сущность m, тип которой определен на верхнем уровне, например, MENU. Всякий актуальный объект, к которому она будет присоединяться во время исполнения, будет, конечно, специфическим для платформы, т. е. будет экземпляром некоторого класса нижнего уровня, скажем, WEL_MENU. Для применения специфических для платформы компонентов требуется некоторая сущность этого типа, скажем wm. Далее можно воспользоваться следующей схемой:
wm ?= m if wm = Void then ... Мы не под Windows! Ничего не делать или заниматься другими делами... else ... Здесь можно применить к wm любой специфический для Windows компонент WEL_MENU ... endМожно описать эту схему, как путь в комнату Windows. Эта комната закрыта, не позволяя утверждать, если кто-нибудь вас в ней обнаружит, что вы попали туда случайно. Вам разрешается в нее войти, но для этого вы должны открыто и вежливо попросить ключ. Попытка присваивания является официальной просьбой разрешения войти в область специального назначения.
Приложения
Последней из главных абстракций данных является понятие приложения.
Все предыдущие абстракции были внутренними средствами. Приложения - это то, что в действительности хотят построить разработчики. Примерами приложений являются системы обработки текстов, системы управления инвестициями, системы управления производством и др.
Для описания приложения необходимо задание множества состояний, переходов между состояниями, выделение одного состояния в качестве начального (с него начинаются все сессии). Мы уже видели, что состояние связывает некоторый отклик с каждой допустимой парой контекст-событие, включающий выполнение некоторой команды. Для полного построения приложения может также потребоваться включение в отклик указания на ту пару контекст-событие, приведшую к этому отклику, так что различные комбинации смогут инициировать переходы в разные состояния. Такую информацию будем называть меткой перехода.
Имея состояния и метки переходов, можно построить диаграмму переходов, описывающую все приложение. На предыдущем рисунке показана часть такой диаграммы для Vi.
Применение ОО-подхода
В ОО-подходе ключевым шагом является выбор правильных абстракций данных: типов объектов, характерных для данной проблемной области.
Для понимания графических интерфейсов пользователей и разработки хороших механизмов создания приложений требуется проанализировать соответствующие абстракции. Некоторые из них очевидны, другие окажутся более тонкими.
Каждая из перечисленных ниже абстракций будет давать хотя бы один библиотечный класс. Некоторые потребуют множества классов, являющихся потомками общего предка, описывающего их самые общие свойства. Например, в библиотеке имеется несколько классов, описывающих разные варианты понятия меню.
Сначала рассмотрим общую структуру переносимой графической библиотеки, затем - основные графические абстракции выводимых на экран геометрических объектов и "объектов взаимодействия", поддерживающих управляемые событиями диалоги, а в конце изучим более продвинутые абстракции, описывающие приложения: команды, состояния, само приложение.
Современные интерактивные приложения управляются событиями:
Современные интерактивные приложения управляются событиями: после того, как интерактивный пользователь своими действиями вызывает появление некоторых событий (их примеры - ввод текста с клавиатуры, движение мыши или нажатие кнопок), выполняются соответствующие им операции.
Хотя это описание выглядит вполне безобидно, в нем заключено главное отличие от традиционных стилей взаимодействия с пользователями. Программа, написанная в старом стиле (еще достаточно распространенном), получает ввод от пользователя, последовательно выполняя сценарий:
... Выполняет некоторые вычисления ... print ("Введите, пожалуйста, значение параметра xxx.") read_input xxx := value_read ... Продолжает вычисление до тех пор, пока снова не потребуется получить некоторое значение от пользователя ...Когда вычислением управляют события, происходит перемена ролей: операции выполняются не оттого, что программа дошла до некоторого заранее заданного этапа своей работы, но потому, что какое-то событие, обычно инициированное интерактивным пользователем, вызвало выполнение некоторого компонента ПО. Входы определяют выполнение ПО, а не наоборот.
ОО-стиль проектирования ПО играет важную роль в реализации такой схемы. В частности, динамическое связывание позволяет программе вызывать компонент объекта, понимая, что тип объекта определяет, как он будет выполнять этот компонент. Вызов компонента может быть связан с событием.
Понятие события настолько важно в этом обсуждении, что заслуживает своей абстракции данных. Объект событие (экземпляр класса EVENT) будет представлять действие пользователя, например, нажатие клавиши, движение мыши, щелчок кнопкой мыши, двойной щелчок и т. д. Эти предопределенные события будут частью каталога событий.
Кроме того, должна быть возможность определять в программах собственные события, сообщения о появлении которых компоненты ПО могут посылать в явном виде с помощью процедуры вида raise(e).
Состояния
Более полная схема включает дополнительный уровень абстракции, дающий модель Контекст-Событие-Команда-Состояние (Context-Event-Command-State) интерактивных графических приложений.
Вообще говоря, комбинация контекст-событие не всегда должна приводить к одинаковому действию в приложении. Например, во время сессии может оказаться ситуация, когда часть экрана выглядит так:

Рис. 14.4. Команда выхода
В этом состоянии приложение распознает различные события в различных контекстах; например, можно щелкнуть по фигуре, чтобы ее передвинуть, или запросить команду сохранения Save, щелкнув кнопку OK. В этом последнем случае появляется новая панель:
Рис. 14.5. Подтверждение команды
На этой стадии будут допустимы только две комбинации контекст-событие: щелчок кнопки OK или щелчок кнопки Cancel на новой панели. Приложение сделает остальную часть изображения "серой", напомнив тем самым, что все, кроме этих двух кнопок, временно не активно. Сессия перешла в новое состояние. Понятие состояния, также иногда называемого режимом, знакомо по дискуссиям об интерактивных системах, но редко определялось точно. Теперь у нас есть предпосылки для формального определения: состояние характеризуется множеством допустимых в нем комбинаций контекстов и событий и множеством команд; для каждой допустимой комбинации контекст-событие состояние задает связанную с ней команду. Ниже это будет переформулировано в виде математического определения.
У многих интерактивных приложений, не только графических, будет несколько состояний.
|
Типичным примером является хорошо известный редактор Vi, работающий под Unix. Поскольку это не графическое средство, то событиями являются нажатия на клавиши (каждой клавише клавиатуры соответствует свое событие), а контекстами являются различные возможные положения курсора (на некотором символе, в начале строки, в конце строки и т. п.). Грубый анализ показывает, что у Vi по крайней мере четыре состояния. |
Например, нажатие на x удаляет символ в позиции курсора, если таковой символ имеется, двоеточие переводит в командное состояние, нажатие на i переводит в состояние вставки, а нажатие R переводит в состояние замены. Некоторые символы не определяют события, например, нажатие z не имеет эффекта (если с ним не связан какой-либо макрос).В командном состоянии единственное, что допустимо, - это ввод команд в окне Vi, таких как "save" или "restart".В состоянии вставки в качестве событий допустимы нажатия клавиш с печатаемыми символами, при этом соответствующий символ вставляется в текст, вызывая сдвиг имеющегося текста вправо. Клавиша ESCAPE возвращает сессию в основное состояние.Состояние замены является вариантом состояния вставки, в котором печатаемые символы заменяют существующие, а не сдвигают их.
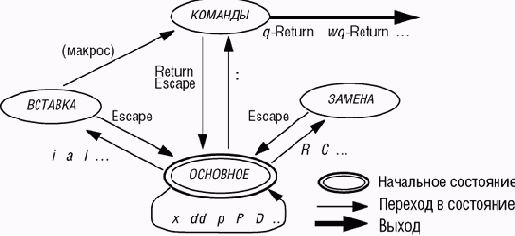
Рис. 14.6. Частичная диаграмма состояний для Vi
Литература по интерфейсам пользователей настроена критически к состояниям, потому что они могут вводить пользователей в заблуждение. В одной старой статье о пользовательском интерфейсе языка Smalltalk [Goldberg 1981] имеется фотография автора в футболке с надписью "Долой режимы!"( "Don't mode me in!"). Действительно, общий принцип разработки хорошего интерфейса пользователя состоит в том, чтобы обеспечить конечным пользователям на каждом этапе сессии возможность выполнять все имеющиеся в их распоряжении команды (вместо того, чтобы заставлять их изменять состояние для выполнения некоторых важных команд).
В соответствии с этим принципом хороший проект постарается минимизировать число состояний. Но этот принцип вовсе не означает, что всегда удастся обойтись одним состоянием. Такая крайняя интерпретация лозунга "долой режимы" может, на самом деле, ухудшить качество интерфейса пользователя, так как чересчур большое количество одновременно доступных несвязанных между собой команд может запутать конечных пользователей. Более того, могут быть веские причины для ограничения числа доступных команд в некоторых ситуациях (например, когда приложению нужен неотложный ответ от своего конечного пользователя).
Как бы там ни было, состояния должны быть явно определены разработчиками и, как правило, должны быть также ясными для конечных пользователей. Это единственный способ, позволяющий разработчикам применять выбранную ими политику интерфейса - независимо от того, сильны ли их предубеждения против режимов или они относятся к ним более терпимо.
Поэтому наш конструктор приложений предоставит разработчикам в явном виде абстракцию STATE (СОСТОЯНИЕ); что касается других абстракций, то в нем будет каталог состояний, содержащий состояния, полезные для общего использования, и редактор состояний, позволяющий разработчикам определять новые состояния, часто получаемые с помощью модификации состояний, извлеченных из каталога.
