Дела косметические!
Хотя правила, представленные здесь, не столь фундаментальны, как принципы ОО-конструирования ПО, было бы глупо рассматривать их просто как "косметику". Хорошее ПО хорошо в большом и в малом - в архитектуре высокого уровня и в деталях низкого уровня. Качество деталей еще не гарантирует качества в целом, но небрежность в деталях верный признак более серьезных ошибок. (Если проект не выглядит красивым, то заказчики не поверят, что вы справились с по-настоящему трудным делом.) Серьезный инженерный процесс требует все делать правильно: великолепно и современно.
Так что не следует пренебрегать, казалось бы, такими пустяками как форматирование текста и выбор имен. Может показаться удивительным перейти, не снижая уровня внимания, от математических понятий достаточной полноты формальных спецификаций к тому, что символу "точка с запятой" должен предшествовать пробел. Объяснение простое: обе проблемы заслуживают внимания аналогично тому, как при создании качественного ПО следует уделять равное внимание проектированию и реализации.
Некоторые подсказки можно получить, исходя из понятия стиля в его литературном смысле. Хотя, говоря о хорошем произведении, на первом месте стоит способность автора создать соответствующую структуру и сюжет, никакой текст не будет успешным, пока в нем не все отработано: каждый абзац, каждое предложение, каждое слово.
Детали отступов
Гребенчатая структура использует отступы, для создания которых используется табуляция (но не пробелы!).
Вот какова иерархия отступов для основных видов конструкции, иллюстрируемых ниже следующим примером:
Уровень 0: ключевые слова, вводящие первичные предложения класса. Они включают: indexing (начинающее предложение индексации), class (начинающее тело класса), feature (начинающее предложение feature, исключая случай, когда feature находится на той же строке, что и class), invariant (начинающее предложение инварианта) и заключительный end класса.Уровень 1: начало объявления компонента - declaration; разделы индексирования; предложения инварианта.Уровень 2: ключевые слова, начинающиеся последующими предложениями подпрограммы. Они включают: require, local, do, once, ensure, rescue, end.Уровень 3: Заголовочный комментарий подпрограмм и атрибутов; объявления локальных сущностей в подпрограмме; инструкции первого уровня.Внутри тела программы может быть своя система отступов при гнездовании управляющих структур. Например, инструкция if a then... содержит две ветви, каждая с отступом. Эти ветви могут сами содержать инструкции цикла или выбора, приводящие к дальнейшему гнездованию. Еще раз заметим, что ОО-стиль этой книги приводит к простым подпрограммам, редко приводящим к высокому уровню гнездования.
Инструкция check задается с отступом. За ней, как правило, следует поясняющий комментарий, располагаемый на следующем уровне справа от охраняемой инструкции.
indexing description: "Пример форматирования" class EXAMPLE inherit MY_PARENT redefine f1, f2 end MY_OTHER_PARENT rename g1 as old_g1, g2 as old_g2 redefine g1 select g2 end creation make feature -- Initialization make is -- Сделать нечто require some_condition: correct (x) local my_entity: MY_TYPE do if a then b; c else other_routine check max2 > max1 + x ^ 2 end -- Из постусловия другой подпрограммы new_value := old_value / (max2 - max1) end end feature -- Access my_attribute: SOME_TYPE -- Объяснение его роли (выровнено с комментарием для make) ... Объявления других компонентов и предложения feature ... invariant upper_bound: x <= y end --class ExampleДисциплина и творчество
Было бы ошибкой протестовать против правил этой лекции на том основании, что они ограничивают творческую активность разработчиков. Согласованный стиль скорее помогает, чем препятствует творчеству, направляя его в нужное русло. Большая часть усилий при производстве ПО тратится на чтение уже существующих текстов. Индивидуальные предпочтения в стиле дают преимущества одному человеку, общие соглашения - помогают каждому.
В программистской литературе семидесятых годов пропагандировалась идея "безликого программирования" ("egoless programming"): разрабатывать ПО так, чтобы личность автора в нем не ощущалась. Ее цель - возможность взаимозаменяемости разработчиков. Примененная к проектированию системы, цель эта становится явно нежелательной, даже если некоторые менеджеры страстно желают этого. Приведу отрывок из книги Барри Боема, цитирующей эту идею: "Программистский творческий инстинкт должен быть полностью затушеван в интересах общности и понятности". Сам Боем комментирует это так: "Давать программистам подобные советы, зная их повышенную мотивацию, - заведомо обрекать их на нервное расстройство".
Какого качества можно ожидать от ПО с безликим проектом и безликим выражением?
Более чем удивительно, но при разработке ПО почти полностью отсутствуют стандарты стиля. Нет другой дисциплины, которая называлась бы "инженерией", где был бы такой простор для персональных прихотей и капризов. Чтобы стать профессионалами, разработчики ПО должны контролировать сами себя и выработать свои стандарты.
Другие соглашения
Предыдущие соглашения о шрифтах хорошо работают для книг, статей, Web-страниц. В некоторых контекстах могут применяться другие подходы. Так при показе слайдов через проектор элементы, записанные курсивом, иногда и полужирным курсивом, не всегда читаются на экране.
В таких случаях я использую следующие соглашения:
использую полужирный некурсивный шрифт для всего, что требует лучшего проектирования;выбираю достаточно широкий шрифт, такой как Bookman;вместо курсива использую цвет для распознавания различных элементов.Форматирование
Рекомендуемое форматирование текста следует из общей синтаксической формы нотации, которую с некоторой натяжкой можно назвать "операторной грамматикой", когда текст класса представляет последовательность символов, разделенных на "операторы" и "операнды". Операторами являются фиксированные символы языка, такие как ключевые слова (do, например) или разделители (точка с запятой, запятая). Операндом является символ, выбираемый программистом (идентификатор, константа).
Основываясь на этом свойстве, форматирование текста следует гребенчато-подобной структуре (comb-like structure), введенной в языке Ada. Идея состоит в том, что каждая синтаксически важная часть класса, такая как инструкция или выражение должна либо:
размещаться на одной строке вместе с предшествующими и последующими операторами;либо с отступами размещаться на нескольких строках, организованных так, чтобы это правило выполнялось рекурсивно.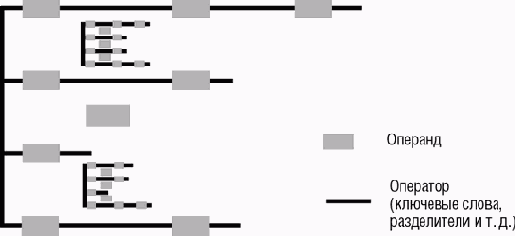
Рис. 8.1. Гребенчато-подобная структура организации программного текста
Каждая ветвь гребенки является последовательностью чередующихся операторов и операндов, обычно начинающихся и заканчивающихся оператором. В пространстве между двумя ветвями находится либо операнд, либо рекурсивно гребенчато-подобная структура.
Как пример, зависящий от размера его составляющих a, b и c, допустимы следующие формы представления инструкции выбора:
if c then a else b endили
if c then a else b endили:
if c then a else b endОднако вы не можете использовать строку, содержащую просто if c или c end, так как они включают операнд вместе с чем-то еще, пропуская заканчивающий оператор в первом случае, а во втором - начинающий.
Подобным образом можно начать класс после предложения indexing так:
class C inherit -- [1]или
class C feature -- [2]или
class -- [3] C featureНельзя писать
class C -- [4] featureпоскольку первая строка нарушает правило.
Формы [1] и [2] используются в этой книге для небольших иллюстративных классов. Более практичные классы имеют одно или несколько помеченных предложений feature, они в отсутствие предложения inherit должны использовать форму [3] (она предпочтительнее, чем форма [2]):
class C feature -- Initialization ... feature -- Access и т.д.Форматирование и презентация текста
Следующие правила определяют, как следует располагать программный текст на бумаге в реальной жизни или при моделировании этого процесса на дисплее компьютера. Более чем любые другие они взывают о "косметике" столь же важной для разработчиков ПО, как косметика от Кристиана Диора для ее покупательниц. Они играют немалую роль в том, как быстро ваш продукт будет понятен его пользователям - сопровождающим, повторно использующим, покупающим ваше ПО.
Где размещать объявления констант
Если число локальных константных атрибутов в классе становится большим, то, вероятно, имеет место нераспознанная абстракция данных - определенное понятие, характеризуемое рядом параметров.
Тогда желательно сгруппировать объявления констант, поместив их в отдельный класс, который может служить предком для любого класса, которому нужны константы. (Некоторые разработчики предпочитают в таких случаях использовать отношение клиента.) Примером является класс ASCII библиотеки Base.
Грамматические категории
Точные правила управляют грамматическими категориями слов, используемых в идентификаторах. В некоторых языках эти правила могут применяться без колебаний, в английском, как ранее отмечалось, они обеспечивают большую гибкость.
Правило для имен классов уже приводилось: следует всегда использовать существительные, как в ACCOUNT, возможно квалифицированные, как в LONG_TERM_SAVINGS_ACCOUNT, за исключением случая отложенных классов, описывающих структурные свойства, для которых могут использоваться прилагательные, как в NUMERIC или REDEEMABLE.
Имена подпрограмм должны отражать принцип Разделения Команд и Запросов:
Процедуры (команды) должны быть глаголами в инфинитиве или повелительной форме, возможно, с дополнениями: make, move, deposit, set_color.Атрибуты и функции (запросы) никогда не должны использовать императив или инфинитив глаголов: никогда не называйте запрос get_value, назовите его просто value. Имена небулевых запросов должны быть существительными, такими как number, возможно, квалифицированными, как в last_month_balance. Булевы запросы должны использовать прилагательные, как в full. В английском возможна путаница между прилагательными и глаголами (empty, например, может значить "пусто ли это?" или "опустошить это!"). В связи с этим для булевых запросов часто применяется is_ форма, как в is_ empty.Использование констант
Многие алгоритмы используют константы. Как отмечалось в одной из предыдущих лекций, у констант плохая слава из-за отвратительной практики изменения их значений. Следует предусмотреть меры против подобного непостоянства.
Комментарии в заголовках: упражнение на сокращение
Подобно дорожным знакам на улицах Нью-Йорка, говорящим "Даже и не думайте здесь парковаться!", знаки на входе в отдел программистов должны предупреждать " Даже и не думайте написать подпрограмму без заголовочного комментария". Этот комментарий, следующий сразу за ключевым словом is, кратко формулирует цель программы; он сохраняется в краткой и плоской краткой форме класса:
distance_to_origin: REAL is -- Расстояние до точки (0, 0) local origin: POINT do create origin Result := distance (origin) endОбратите внимание на отступ: комментарий начинается на шаг правее тела подпрограммы.
Комментарий к заголовку должен быть информативным, кратким, ясным. Он имеет собственный стиль, которому будем обучаться на примере, начав вначале с несовершенного комментария, а затем улучшая его шаг за шагом. В классе CIRCLE к одному из запросов возможен такой комментарий:
tangent_from (p: POINT): LINE is -- Возвращает касательную линию к текущей -- окружности, -- проходящую через данную точку p, -- если эта точка лежит вне текущей окружности require outside_circle: not has (p) ...В стиле этого комментария много ошибок. Во-первых, он не должен начинаться "Возвращает ..." или "Вычисляет ... ", используя глагольные формы, поскольку это противоречит принципу Разделения Команд и Запросов. Имя, возвращаемое не булевым запросом, типично использует квалифицированное существительное. Поэтому лучше написать так:
-- Касательная линия к текущей окружности, -- проходящая через данную точку p, -- если эта точка лежит вне текущей окружностиТак как комментарий теперь не предложение, а просто квалифицированное имя, то точку в конце ставить не надо. Теперь следует избавиться от дополнительных слов (в английском особенно от the), не требуемых для понимания. Для комментариев желателен телеграфный стиль. (Помните, что читатели, любящие литературные красоты, могут выбрать для чтения романы Марселя Пруста.)
-- Касательная линия к текущей окружности, -- проходящая через точку p, -- если точка вне текущей окружностиСледующая ошибка содержится в последней строчке.
Дело в том, что условие применимости подпрограммы - ее предусловие - not has (p), появится сразу после комментария в краткой форме, где оно выражено ясно и недвусмысленно. Поэтому нет необходимости в его перефразировке, что может привести только к путанице, а иногда и к ошибкам (типичная ситуация: предусловие в форме x >= 0 с комментарием "применимо только для положительных x", а нужно "не отрицательных"); всегда есть риск при изменившемся предусловии забыть об изменении комментария. Наш пример теперь станет выглядеть так:
-- Касательная линия к текущей окружности из точки pЕще одна ошибка состоит в использовании слов линия (line) и точка (point) при ссылках на результат и аргумент запроса: эта информация непосредственно следует из объявляемых типов LINE и POINT. Лучше использовать формальные объявления типов, которые появятся в краткой форме, чем сообщать эту информацию в неформальной форме комментария. Итак:
-- Касательная к текущей окружности из pНаши ошибки состояли в излишнем дублировании информации - о типах, о требованиях предусловия. Из их анализа следует общее правило написания комментариев: исходите из того, что читатель компетентен в основах технологии, не включайте информацию, непосредственно доступную в краткой форме класса. Это, конечно, не означает, что никогда не следует указывать информацию о типах, например, в предыдущем примере Расстояние до точки (0,0) было бы двусмысленным без указания слова "точка" (point).
При необходимости сослаться на текущий экземпляр используйте фразы вида: текущая окружность, текущее число, вместо явной ссылки на сущность Current. Во многих случаях можно вообще избежать с упоминания текущего объекта, так как каждому программисту ясно, что компоненты при вызове применяются к текущему объекту. В данном примере наш заключительный комментарий выглядит так:
-- Касательная из pНа этом этапе осталось три слова, а начинали с трех строк из 18 длинных слов. Длина комментария сократилась примерно на 87%, мы можем считать, что упражнение на сокращение выполнено полностью, - сказать короче и яснее трудно.
Несколько общих замечаний. Отметим бесполезность в запросах фраз типа "Возвращает ...", других шумовых слов и фраз, которые следует избегать во всех подпрограммах: "Эта подпрограмма вычисляет (возвращает) ...", просто скажите, что делается. Вместо:
-- Эта программа записывает последний исходящий звонокпишите
-- Записать исходящий звонокКак показывает это пример, комментарий к командам (процедурам) должен быть в императивной или инфинитивной форме (в английском это одно и тоже). Он должен иметь стиль приказа и оканчиваться точкой. Для булевых запросов комментарий всегда должен быть в вопросительной форме и заканчиваться знаком вопроса:
has (v: G): BOOLEAN is -- Появляется ли v в списке? ...Соглашение управляет использованием программных сущностей - атрибутов, аргументов, появляющихся в комментариях. При наборе текста они выделяются курсивом (о других соглашениях на шрифт смотри ниже). В исходных программных текстах они всегда должны заключаться в кавычки, так что оригинальный текст выглядит так:
-- Появляется ли 'v' в списке?Инструментарий, генерирующий краткую форму класса, использует это соглашение для обнаружения ссылок на сущности.
Нужно следить за согласованностью. Если функция класса имеет комментарий: "Длина строки", в другой процедуре не должна идти речь о "ширине" строки: "Изменить ширину строки", когда речь идет об одном и том же свойстве строки.
Все эти рекомендации применимы к подпрограммам. Поскольку экспортируемые атрибуты внешне ничем не должны отличаться от функций без аргументов, то они тоже имеют комментарий, появляющийся с тем же отступом, что и у функций:
count: INTEGER -- Число студентов на курсеДля закрытых атрибутов комментарии желательны, но требования к ним менее строгие.
Кратко и явно
Стиль ПО всегда колебался между краткостью и многословием. Двумя крайними примерами языков программирования являются, вероятно, APL и Cobol. Контраст между линейкой языков Fortran-C-C++ и традициями Algol-Pascal-Ada - не только в самих языках, но в стиле, который они проповедуют, - разителен.
Существенными для нас являются ясность и качество. Обе экстремальные формы противоречат этим целям. Зашифрованные C-программы, к несчастью, не ограничены известной дискуссией об "obfuscated (затемненном, сбивающем с толку) C и C++". В равной степени почти столь же известные многословные выражения (DIVIDE DAYS BY 7 GIVING WEEKS) языка Cobol являются примером напрасной траты времени.
Стиль правил этой лекций представляет смесь ясности, характерной для Algol-подобных языков и краткости телеграфного стиля. Он никогда не скупится на нажатия клавиш, когда они по-настоящему способствуют пониманию программного текста. Например, одно из правил предписывает задание идентификаторов словами, а не аббревиатурами; было бы глупо экономить несколько букв, назвав компонент disp (двусмысленно), а не display (ясно и четко), или класс ACCNT (непроизносимое) вместо ACCOUNT. В данных ситуациях нет налога на число нажатий. Но в то же время, когда приходится исключать напрасную избыточность, правила безжалостны. Они ограничивают заголовки комментариев обязательными словами, освобождают от всех "the" и других подобных любезностей; они запрещают излишнюю квалификацию (подобную account_balance в классе ACCOUNT, где имени balance достаточно). Возвращаясь к доминантной теме, правила допускают группирование связанных составляющих сложной структуры в одной сроке, например:
from i := 1 invariant i <= n until i = n loop.Этой комбинации ясности и краткости следует добиваться в своих текстах. Раздутый размер текста, в конечном счете, приводят к возрастанию сложности, но и не экономьте на размере, когда это необходимо для обеспечения ясности.
Если, подобно многим, вас интересует, будет ли текст ОО-реализации меньше, чем текст на языках C, Pascal, Ada или Fortran, то интересный ответ появится только на уровне большой системы или подсистемы.
При записи основных алгоритмов, подобных быстрой сортировке Quicksort, или алгоритма Эвклида ОО-версия будет не меньше, чем на C, в большинстве случаев при следовании правилам стиля она будет больше, так как будет включать утверждения и подробную информацию о типах. Все же по опыту ISE на системах среднего размера мы иногда находили (не утверждаем, что это общее правило), что ОО-решение было в несколько раз короче. Почему? Дело не в краткости на микроуровне, результат объясняется широким применением архитектурных приемов ОО-метода:
Универсальность - один из ключевых факторов. Мы обнаруживали в программах C один и тот же код, многократно повторяющийся для описания различных типов. С родовыми классами или с родовыми пакетами Ada вы избавляетесь от подобной избыточности. Огорчительно видеть, что Java, ОО-язык, основанный на C, не поддерживает универсальность.Наследование вносит фундаментальный вклад в сбор общности и удаление дублирования.Динамическое связывание заменяет многие сложные структуры разбора ситуаций, делая вызовы много короче.Утверждения и связанная с ними идея Проектирования по Контракту позволяет избегать избыточных проверок - принципиального источника раздувания текста.Механизм исключений позволяет избегать написания некоторого кода, связанного с обработкой ошибок.Если вас заботят размеры кода, убедитесь, что вы позаботились об архитектурных аспектах. Следует быть краткими при выражении сути алгоритма, но не экономьте на нажатиях клавиш ценой ясности.
Локальные сущности и аргументы подпрограмм
Акцент на ясные, хорошо произносимые имена сделан для компонентов и классов. Для локальных сущностей и аргументов подпрограмм, имеющих локальную область действия, нет необходимости в подобной выразительности. Имена, несущие слишком много смысла, могут даже ухудшить читабельность текста, придавая слишком большое значение вспомогательным элементам. (Им можно давать короткие однобуквенные имена, как, например, в процедуре класса TWO_WAY_LIST из библиотеки e Base)
move (i: INTEGER) is -- Поместить курсор в позицию i или after, если i слишком велико local c: CURSOR; counter: INTEGER; p: like FIRST_ELEMENT ... remove is -- Удаляет текущий элемент; перемещает cursor к правому соседу -- (или after если он отсутствует). local succ, pred, removed: like first_element ...Если бы succ и pred были бы компонентами, они бы назывались successor и predecessor. Принято использовать имя new для локальной сущности, представляющей новый объект, создаваемый программой, и имя other для аргумента, представляющего объект того же типа, что и текущий, как в объявлении для clone в GENERAL:
frozen clone (other: GENERAL): like other is...Манифестные и символические константы
Основное правило использования констант утверждает, что не следует явно полагаться на значения:
|
Принцип Символических констант Не используйте манифестные (неименованные) константы в любых конструкциях, отличных от объявления символических констант. Исключением являются нулевые элементы основных операций. |
Манифестная константа задается явно своим значением, как, например, 50 (целочисленная константа) или "Cannot find file" (строковая константа). Принцип запрещает использование инструкций в форме:
population_array.make (1, 50)или
print ("Cannot find file") -- Ниже смотри смягчающий комментарийВместо этого следует объявить соответствующий константный атрибут и в телах подпрограмм, где требуются значения, обозначать их именами атрибутов:
US_state_count: INTEGER is 50 file_not_found: STRING is "Cannot find file" ... population_array.make (1, state_count) ... print (file_not_found)Преимущества очевидны: если появится новый штат или изменится сообщение, достаточно изменить только одно объявление.
Использование 1 наряду со state_count в первой инструкции не является нарушением принципа, так как он запрещает манифестные константы, отличные от нулевых элементов. Нулевыми элементами, допустимыми в манифестной форме, являются целые 0 и 1 (нулевые элементы сложения и умножения), вещественное число 0.0, нулевой символ, записываемый как '%0', пустая строка - "". Использование символической константы One каждый раз, когда требуется сослаться на нижнюю границу массива (1 используется соглашением умолчания), свидетельствовало бы о педантичности, фактически вело бы к ухудшению читабельности.
|
В других обстоятельствах 1 может просто представлять системный параметр, имеющий сегодня одно значение, а завтра другое. Тогда следует объявить символическую константу, как например Processor_count: INTEGER is 1 в многопроцессорной системе, использующей пока один процессор. |
Принцип Символических Констант слишком строг в случае простых, однократно применяемых манифестных строк. Можно было бы усилить исключение, сформулировав его так: "за исключением нулевых элементов основных операций и манифестных строковых констант, используемых однократно". В примерах этой книги используются такие константы. Такое ослабление правила приемлемо, но в долгосрочной перспективе лучше придерживаться правила в первоначальной форме, даже если это кажется педантичным. Одно из главных применений строковых констант - это вывод сообщений пользователю. Когда успешная система, выпущенная для национального рынка, выходит на международный, то с символическими константами переход на любой язык не представляет трудностей.
Не заголовочные комментарии
Предыдущие правила применяются к стандартизованным комментариям, появляющимся в определенных местах и играющих специальную роль в документировании класса.
Во всех способах разработки ПО существует необходимость в комментариях отдельных участков выполняемых алгоритмов, поясняющих суть работы.
|
Есть еще одно использование комментариев, часто используемое на практике, но редко упоминаемое в учебниках. Я говорю здесь о технике преобразования некоторого участка кода в комментарий либо потому, что он не работает, либо он еще просто не готов. Эта практика, очевидно, требует замены специальными механизмами. Она уже обогатила язык новой глагольной формой - "закомментировать" (comment out). |
Каждый комментарий по уровню абстракции должен быть выше комментируемого примера. Известный контрпример: -- Увеличить i на 1 в инструкции i := i + 1. Здесь комментарий является перефразировкой кода и не несет полезной нагрузки.
Языки низкого уровня призывают к подробному комментированию. Каждую строку C следует комментировать, поскольку в современной разработке языку C отводится роль инкапсуляции машинно-ориентированных операций и выполнения функций уровня операционной системы, что по своей природе является неким видом трюкачества и потому требует пояснений. В ОО-разработках комментарии, не относящиеся к заголовкам, встречаются значительно реже, они остаются необходимыми для тонких мест разработки и тогда, когда предвидится возможное смешение понятий. В своих постоянных усилиях предотвратить появление ошибок, а не лечить их последствия, метод уменьшает необходимость в комментариях благодаря модульному стилю, выработке небольших, понятных подпрограмм, через механизм утверждений. Предусловия и постусловия, инварианты класса формально выражают семантику, инструкции check выражают ожидаемые свойства, которые должны выполняться в определенном состоянии. Этому способствуют и соглашения именования, введенные в этой лекции. Общий тезис: секрет в создании ясного, понятного ПО состоит не в постфактумном добавлении комментариев, но в производстве согласованной и стабильной структуры системы, правильной с самого начала.
Общие правила
Наиболее значимыми являются имена классов и компонентов, широко используемые в других классах.
Для этих имен используйте полные слова, но не аббревиатуры, если только последние не имеют широкого применения в проблемной области. В классе PART, описывающем детали в системе управления складом, назовите number, а не num, компонент (запрос), возвращающий номер детали. Печатание недорого стоит, сопровождение - чрезвычайно дорого. Аббревиатуры usa в Географической Информационной системе или copter в системе управления полетами вполне приемлемы, так как в данных областях приобрели статус независимых слов. Кроме того, некоторые сокращения используются годами и также приобрели независимый статус, такие как PART для PARTIAL , например в имени класса PART_COMPARABLE, описывающего объекты, поставляемые с частичным порядком.
При выборе имен целью является ясность. Без колебаний используйте несколько слов, объединенных пробелами, как в имени класса ANNUAL_RATE, или yearly_premium в имени компонента.
Хотя современные языки не ограничивают длину идентификаторов, и рассматривают все буквы как важные, длина имени должна оставаться разумной. Правила на этот счет для классов и компонентов различные. Имена классов вводятся только в ряде случаев - в заголовках класса, объявлениях типа, предложениях наследования и других. Имя класса должно полностью характеризовать соответствующую абстракцию данных, так что вполне допустимо такое имя класса - PRODUCT_QUANTITY_INDEX_ EVALUATOR. Для компонентов достаточно двух слов, редко трех, соединенных подчеркиванием. В частности, не следует допускать излишней квалификации имени компонента. Если имя компонента чересчур длинно, то это, как правило, из-за излишней квалификации.
|
Правило: Составные имена компонентов Не включайте в имя компонента имя базовой абстракции данных (служащей именем класса). |
Компонент, задающий номер части в PART, должен называться просто number, а не part_number. Подобная сверхквалификация является типичной ошибкой новичков, скорее затуманивающей, чем проясняющей текст.
Помните, каждое использование компонента однозначно определяет класс, например part1.number, где part1 должно быть объявлено типа PART или его потомка.
Для составных имен лучше избегать стиля, популяризируемого Smalltalk и используемого в библиотеках, таких как X Window System, объединяющих несколько слов вместе, начиная каждое внутренне слово с большой буквы, как в yearlyPremium. Вместо этого разделяйте компоненты подчеркиванием, как в yearly_premium. Использование внутренних больших букв конфликтует с соглашениями обычного языка и выглядит безобразно, оно приводит к трудно распознаваемому виду, следовательно, к ошибкам (сравните aLongAndRatherUnreadableIdentifier и an_even_longer_but_perfectly_clear_choice_of_name).
Иногда каждый экземпляр некоторого класса содержит поле, представляющее экземпляр другого класса. Это приводит к мысли использовать для имени атрибута имя класса. Например, вы определили класс RATE, а классу ACCOUNT потребовался один атрибут типа RATE, для которого кажется естественным использовать имя rate - в нижнем регистре, в соответствии с правилами, устанавливаемыми ниже. Хотя можно пытаться найти более специфическое имя, но приемлемо rate: RATE. Правила выбора идентификаторов допускают одинаковые имена компонента и класса. Нарушением стиля является добавление префикса the, как в the_rate, что только добавляет шумовую помеху.
Основные правила
Используйте для программных элементов (имен классов, компонентов, сущностей и так далее) курсив. Это облегчает их включение в предложения обычного текста, как, например, "Можно видеть, что компонент number является запросом, а не атрибутом". (Слово number означает имя компонента, и вы не хотите, чтобы читатель мог подумать, что речь идет о числе компонентов!)
Ключевые слова, такие как class, feature, invariant и другие, набираются полужирным шрифтом (boldface).
Ключевые слова играют чисто синтаксическую роль: они не имеют собственной семантики. Как отмечалось ранее, есть несколько зарезервированных слов, не являющихся ключевыми, таких как Current и Result, обладающих семантикой выражений или сущностей. Они пишутся курсивом с начальным символом в верхнем регистре.
Следуя традициям математики, разделители - двоеточия, запятые, различные скобки и другие - всегда появляются прямыми (шрифтом roman), даже если они стоят после курсива1). Подобно ключевым словам, они являются чисто синтаксическими элементами.
Текст комментария пишется прямым (roman) шрифтом. Имена программных элементов, в соответствии с ранее введенным правилом, даются в комментариях, курсивом. Например:
accelerate (s: SPEED; t: REAL) is -- Развить скорость s за максимум t секунд ... set_number (n: INTEGER) is -- Сделать n новым значением number ...В самих программных текстах, где невозможны вариации шрифта, такие вхождения формальных элементов в комментарии должны следовать соглашениям, уже упоминавшимся ранее: они появляются в одинарных кавычках
-- Сделать 'n' новым значением 'number'(Заметьте, следует использовать разные символы для открывающей и закрывающей кавычки.) Инструментальные средства, обрабатывающие текст класса, такие как short и flat, знают об этом соглашении и при печати выводят закавыченные элементы курсивом.
Предложения индексирования
Подобными заголовочным комментариям, но немного более формальными являются предложения индексирования, появляющиеся в начале каждого класса:
indexing description: "Последовательные списки в цепном представлении" names: "Sequence", "List" contents: GENERIC representation: chained date: "$Date: 96/10/20 12:21:03 $" revision: "$Revision: 2.4$" ... class LINKED_LIST [G] inherit ...Предложения индексирования строятся в соответствии с принципом Само-документирования аналогично встроенным утверждениям и заголовочным комментариям, позволяя включать в текст ПО возможную документацию. Для свойств, не появляющихся напрямую в программном тексте класса, можно включить индексирующие разделы в форме:
indexing_term: indexing_value, indexing_value, ...где indexing_term является идентификатором, а каждое indexing_value является некоторым базисным элементом, таким как строка, целое и так далее. Идентификаторы разделов, имеющие альтернативные имена, позволяют потенциальным авторам клиентов отыскать нужный класс по именам (names), содержанию (contents), выбору представления (representation), информации об обновлениях (revision), информации об авторе и многому другому. В разделы включается все, что может облегчить понимание класса и поиск, использующий ключевые слова. Благодаря специальному инструментарию, поддерживающим повторное использование, облегчается задача разработчиков по поиску в библиотеках нужных им классов с нужными компонентами.
Как индексирующие термы, так и их значения могут быть произвольными, но возможности выбора фиксируются для каждого проекта. Множество стандартов, принятых в библиотеке Base, частично приведено в примере. Каждый класс должен иметь раздел description, значением которого index_value является строка, описывающая роль класса в терминах его экземпляров (Последовательные списки..., но не "этот класс описывает последовательные списки", или "последовательный список", или "понятие последовательного списка" и т. д.). Для наиболее важных классов в этой книге - но не в коротких примерах, предназначенных для специальных целей - раздел description включался в предложение indexing.
Преимущества согласованного именования
Схема имен, данная выше, вносит наиболее видимый вклад в характерный стиль конструирования ПО, разрабатываемый в соответствии с принципами этой книги.
Не зашли ли мы слишком далеко в борьбе за согласованность? Не получится ли, что в программах будут использоваться одни и те же имена, но с разной семантикой? Например, item для стека возвращает элемент вершины, а для массива - элемент с заданным индексом.
При систематическом подходе к ОО-конструированию, использованию статической типизации и Проектированию по Контракту этот страх не оправдан. Знакомясь с компонентом, автор клиента может полагаться на четыре вида свойств, представленных в краткой форме класса:
F1 Его имя.F2 Его сигнатура (число и типы аргументов, если это процедура, тип результата для запросов).F3 Предусловие и постусловие, если они заданы.F4 Заголовочный комментарий.|
Подпрограммы имеют, конечно же, тело, но предполагается, что тело не должно волновать клиента. |
Три из этих элементов будут отличаться для вариантов базисных операций. Например, в краткой форме класса STACK можно найти компонент:
put (x: G) -- Втолкнуть x на вершину require writable: not full ensure not_empty: not empty pushed: item = xВ классе ARRAY появляется однофамилец:
put (x: G; i: INTEGER) -- Заменить на x значение элемента с индексом i require not_too_small: i >= lower not_too_large: i <= upper ensure replaced: item (i) = xСигнатуры различаются, предусловия, постусловия, заголовочные комментарии - все различно. Использование имени put, не создавая путаницы, обращает внимание читателя на общую роль этих процедур: они обе обеспечивают базисный механизм изменений.
Эта согласованность оказывается одним из наиболее привлекательных аспектов метода, в частности библиотек. Новые пользователи быстро привыкают к ней и при появлении нового класса, следующего стандартному стилю, принимают его как старого знакомого и могут сразу же сосредоточиться на нужных им компонентах.
Применение правил на практике
Можно проверять, выполняются ли правила стиля. Лучше, если они навязаны инструментарием и выполняются изначально. Однако инструментарий позволяет далеко не все, и нет замены тщательности в написании каждого участка ПО.
Часто программист откладывает применение правил стиля. Он пишет программный код как придется, полагая: "я почищу все позже, сейчас я даже не знаю, что из написанного мне пригодится". Это не наш путь. Если правило используется, не должно быть никакой задержки в его применении с первых шагов написания ПО, даже в отсутствие специальных средств поддержки. Всегда дороже последующие корректировки текста, чем его корректное написание с самого начала. Всегда есть риск, что на чистку не хватит времени или вы просто забудете о ней. Всякий, кто позже столкнется с вашей работой, потратит куда больше времени, чем это стоило бы вам при написании заголовочных комментариев, придумывании подходящих имен, применении нужного форматирования. Не забывайте: этим кто-то можете быть вы сами.
Приоритеты и скобки
Соглашения о приоритетах в нотации соответствуют традициям и принципу Наименьших Сюрпризов во избежание ошибок и двусмысленностей.
Для ясности добавляйте скобки без колебаний; например, вы можете написать (a = (b + c)) implies (u /= v) несмотря на то, что смысл этого выражения не изменится, если все скобки будут опущены. В примерах этой книги зачастую расставлены "лишние" скобки, особенно в утверждениях, возможно, утяжеляя выражение, но избегая неопределенности.
Пробелы
Белые пробелы (пробелы, табуляция, символы окончания строки) производят такой же эффект в программных текстах, как паузы в нотной записи.
Общее правило состоит в следовании, насколько это возможно, общепринятой практике обычного письменного языка. По умолчанию таковым языком является английский, хотя возможна адаптация правил к другим языкам.
Вот некоторые из следствий. Используйте пробелы:
Перед открывающей скобкой, но не после: f (x) (но не f(x) в стиле C, или f(x)).После закрывающей скобки, если только следующим символом не является знак пунктуации, такой как точка или точка с запятой, но не перед скобкой. Следовательно: proc1 (x); x := f1 (x) + f2 (y).После запятой, но не перед: g (x, y, z).После двух тире, указывающих на начало комментария: -- Комментарий.Аналогично, по умолчанию пробел ставится после, но не перед точкой с запятой:
p1; p2 (x); p3 (y, z)Однако некоторые люди предпочитают французский стиль написания, согласно которому пробелы ставятся и до и после точки с запятой:
p1 ; p2 (x) ; p3 (y, z)Выбирайте любой стиль, но применяйте его согласованно. (Эта книга использует английский стиль.) Английский и французский стили отличаются и для двоеточий. И здесь английский стиль предпочтительнее, как в your_entity: YOUR_TYPE.
Пробелы должны появляться до и после арифметических операций, как в a + b. (В этой книге из экономии пробелы могут опускаться, например в выражении n+1.)
Для точек нотация отходит от соглашений, принятых в естественном языке, поскольку точки используются в специальной конструкции, первоначально введенной в языке Simula. Как вы знаете, a.r означает: применить компонент r к объекту, присоединенному к a. Здесь не должно быть никаких пробелов ни до, ни после точки. В вещественных числах, таких как 3.14, используется обычная точка.
Регистр
Регистр не важен в нашей нотации, поскольку было бы опасным позволять двум почти идентичным идентификаторам обозначать разные вещи. Но настоятельно рекомендуется в интересах читабельности и согласованности придерживаться следующих правил:
Имена классов задаются буквами в верхнем регистре: POINT, LINKED_LIST, PRICING_MODEL. Это верно и для формальных родовых параметров, обычно начинающихся с G.Имена неконстантных атрибутов, подпрограмм, отличных от однократных, локальных сущностей и аргументов подпрограмм задаются полностью в нижнем регистре: balance, deposit, succ, i.Константные атрибуты начинаются с буквы в верхнем регистре, за которой следуют буквы нижнего регистра: Pi: INTEGER is 3.141598524; Welcome_message: STRING is "Welcome!". Это же правило применяется к уникальным значениям, представляющих константные целые.Те же соглашения применяются к однократным функциям, эквиваленту констант для небазисных типов: Error_window, Io. В нашем первом примере комплексное число i (мнимая единица) осталось в нижнем регистре для совместимости с математическими соглашениями.Эти правила касаются имен, выбираемых разработчиком. Резервируемые слова нотации разделяются на две категории. Ключевые слова, такие как do и class, играют важную синтаксическую роль; они записаны в нижнем регистре полужирным шрифтом. Несколько зарезервированных слов не являются ключевыми, поскольку играют ассоциированную семантическую роль, они записываются курсивом с начальной буквой в верхнем регистре, подобно константам. К ним относятся: Current, Result, Precursor, True и False.
Роль соглашений
Большинство правил дает однозначное толкование без всяких вариантов. Исключения включают использование шрифтов, управляемое внешними обстоятельствами (что хорошо выглядит в книге, может быть не видимо на слайдах проектора), и точки с запятыми, для которых существуют две противоположные школы с весомыми аргументами.
Правила появились в результате многолетних наблюдений, дискуссий и тщательного анализа того, что работает и что работает менее хорошо. Даже при этом часть правил может показаться спорной и некоторые решения являются делом вкуса, так что разумные люди по ряду соображений могут с ними не согласиться. Если вы не принимаете какое-либо из рекомендуемых соглашений, вам следует определить свое собственное, пояснить его во всех деталях, явно документировать. Но тщательно все взвесьте, прежде чем принимать такое решение, - так очевидны преимущества универсального множества правил, систематически применяемых к тысячам классам в течение более десяти лет, известных и принятых многими людьми.
Многие из этих правил стиля первоначально разрабатывались для библиотек, а затем нашли свое место в разработке обычного ПО. В объектной технологии, конечно, все ПО разрабатывается в предположении, что, если оно и не предназначается для повторного использования, со временем оно может стать таковым, поэтому естественно с самого начала применять те же правила стиля.
Самоприменение
Подобно правилам проектирования, правила стиля применяются в примерах этой книги. Причины очевидны: каждый должен практиковать то, что он проповедует, не говоря о том, что правила способствуют ясности мысли и выражения при представлении ОО-метода.
Единственными исключениями являются некоторые отходы в форматировании программных текстов. Согласно правилам, программные тексты без колебаний следует располагать на многих строчках, требуя лишь, например, чтобы каждое предложение утверждения имело свою собственную метку. Строки компьютерного экрана не являются ресурсом, который нуждается в экономии. Полагается, что со временем будет произведена революция, и мы перейдем от стиля папирусных свитков к странично-структурированным книгам. Но данный текст определенно является книгой - постоянное применение правил форматирования программных текстов привело бы к неоправданному увеличению объема книги.
Эти случаи освобождения от обязательств распространяются лишь на несколько правил форматирования и будут специально отмечены ниже при представлении правил. Такие исключения разрешаются только для представлений на бумаге. Фактические программные тексты применяют правила буквально.
Шрифты
При наборе программных текстов рекомендуются следующие соглашения, используемые в этой книге и связанных публикациях.
Стандартные имена
Вы уже заметили многократное использование во всей книге нескольких базисных имен, таких как put и item. Они являются важной частью метода.
Большинству классов необходимы компоненты, представляющие операции нескольких базисных видов: вставка, замена, доступ к элементам структуры. Вместо придумывания специальных имен для этих и подобных операций в каждом классе, предпочтительно повсюду применять стандартную терминологию.
Вот каковы основные стандартные имена. Начнем с процедур создания: имя make рекомендуется для наиболее общей процедуры создания и имена вида make_some_qualification, например, make_polar и make_cartesian для классов POINT или COMPLEX.
Для команд наиболее общие имена приведены в таблице:
| extend | Добавить элемент |
| replace | Заменить элемент |
| force | Подобна команде put, но может работать для большего числа случаев. Например для массивов put имеет предусловие, требующее, чтобы индекс не выходил за границы, в то время как force не имеет предусловий и допускает выход за границы |
| remove | Удаляет (не специфицированный) элемент |
| prune | Удаляет специфицированный элемент |
| wipe_out | Удаляет все элементы |
Для небулевых запросов (атрибутов или функций)
| item | Базисный запрос для получения элемента: в классе ARRAY - элемент с заданным индексом; STACK - элемент вершины стека; QUEUE - "старейший" элемент и так далее |
| infix "@" | Синоним item в некоторых случаях, например в классе ARRAY |
| count | Число используемых элементов структуры |
| capacity | Физический размер, распределенный для ограниченной структуры, измеряемый числом потенциальных элементов. Инвариант должен включать 0<count and count <= capacity |
Для булевых запросов стандартными именами являются:
| empty | Содержит ли структура элементы? |
| full | Заполнена ли структура ограниченной емкости элементами? Обычно эквивалент count = capacity |
| has | Присутствует ли заданный элемент в структуре? (Базисный тест проверки членства) |
| extendible | Можно ли добавить элемент? (Может служить предусловием для extend) |
| prunable | Можно ли удалить элемент? (Может служить предусловием для remove и prune) |
| readable | Доступен ли элемент? (Может служить предусловием для remove и item) |
| writable | Можно ли изменить элемент? (Может служить предусловием для extend, replace, put и др.) |
У8.1 Стиль заголовочных комментариев
Перепишите следующий заголовочный комментарий в более подходящем стиле:
reorder (s: SUPPLIER; t: TIME) is -- Повторно заказывает текущую деталь у поставщика s, -- которую следует доставить до достижения срока t; -- эта программа работает только при условии, -- что срок поставки еще не истек require not_in_past: t >= Now ... next_reorder_date: TIME is -- Выдает следующий срок, к которому текущая деталь -- должна быть повторно заказанаУ8.2 Неоднозначность точки с запятой
Можете ли вы придумать случай, при котором пропуск точки с запятой между двумя инструкциями или утверждениями станет причиной синтаксической неоднозначности, или, по меньшей мере, создавал бы помехи наивному грамматическому разбору?
Подсказка: компонент может иметь в качестве цели выражение в скобках, как в (vector1 + vector2).count.
 |
|
|
2) В русском издании книги в отличие от оригинала, к сожалению, применяется черно-белая печать.
Утверждения
Следует именовать утверждения для большей читабельности текста:
require not_too_small: index >= lowerЭто соглашение способствует созданию полезной информации при тестировании и отладке, поскольку, как вы помните (см. лекцию 11 курса "Основы объектно-ориентированного программирования"), метка утверждения включается в сообщение периода выполнения, создаваемое при нарушениях утверждений при включенном их мониторинге.
Это соглашение распространяется на утверждения, состоящих из нескольких предложений, расположенных на разных строках. В данной книге, опять-таки по соображениям экономии объема, метки опускаются, когда несколько утверждений располагаются на одной строке:
require index >= lower; index <= upperПри нормальных обстоятельствах лучше придерживаться официального правила и иметь по одному помеченному предложению утверждения на каждой строке текста.
Война вокруг точек с запятыми
С давних пор два равно известных клана живут в компьютерном мире и вражда между ними столь же ожесточена, как и в Вероне. Сепаратисты, наследники Algol и Pascal, сражаются за то, чтобы точка с запятой служила разделителем инструкций. Терминалисты, объединившиеся под знаменами PL/I, C и Ada, хотят каждую инструкцию завершать точкой с запятой.
Пропагандистские машины обеих сторон приводит бесконечные аргументы в свою пользу. Культом Терминалистов является единообразие: если каждая инструкция завершается одним и тем же маркером, никто и не посмеет задавать вопрос "должен ли я здесь ставить точку с запятой?" (ответ в языках Терминалистов всегда - да, и всякого, кто нарушит предписание, ждет кара за измену). Они не хотят, чтобы нужно было удалять или добавлять этот символ при изменении местоположения инструкции, например, удаляя или внося ее в тело инструкции выбора.
Сепаратисты возносят хвалу элегантности их соглашения и его совместимости с математической практикой. Они рассматривают do instruction1; instruction2; instruction3 end как естественного родственника f (argument1, argument2, argument3). Кто в здравом уме, спрашивают они, предпочел бы писать f (argument1, argument2, argument3,) с ненужной заключительной запятой? Более того, они утверждают, что Терминалисты фактически являются защитниками Компиляторщиков, жестоких людей, чьей единственной целью является обеспечение легкой жизни для разработчиков компиляторов, даже если это приведет к трудной жизни разработчиков приложений.
Сепаратисты должны постоянно бороться с инсинуациями, например, что их языки не позволяют лишних точек с запятой. Снова и снова они должны повторять истину: что каждый язык, заслуживающий этого имени, начиная с признанного патриарха этого племени, Algol 60, поддерживает понятие пустой инструкции, допускающей все виды написания:
a; b; c a; b; c; ; a ;; b ;;; c;Все строки здесь синтаксически правильны и эквивалентны. Они отличаются лишь наличием пустых инструкций в двух последних строках, которые любой уважающий себя компилятор спокойно удалит.
Они указывают, насколько терпимее их соглашение, чем правило фанатичных соперников, когда каждая пропущенная точка с запятой является поводом для атак. Они же готовы принять столько точек с запятой, сколько Терминалисты в силу привычки захотят добавить в тексты Сепаратистов.
Методы современной пропаганды нуждаются в научном обосновании и статистике. В 1975 году Терминалисты провели исследование ошибок, для чего две группы программистов по 25 человек в каждой использовали языки, отличающихся, среди прочего, соглашениями о точках с запятой. Его результаты широко цитировались и послужили оправданием терминалистского соглашения в языке Ada. Из этих результатов следовало, что стиль Сепаратистов привел к десятикратному увеличению ошибок!
Взволнованные непрекращающейся вражеской пропагандой лидеры Сепаратистов обратились за помощью к автору настоящей книги, который, к счастью, вспомнил давно забытый принцип: цитаты хороши, но лучше прочитать первоисточник. Обратившись к оригинальной статье, он обнаружил, что язык Сепаратистов, используемый в сравнении, представлял мини-язык, предназначенный только для обучения студентов концепциям асинхронных процессов, в котором лишняя точка с запятой, как в begin a; b; end, рассматривалась как ошибка! Ни один реальный язык Сепаратистов, как отмечалось выше, такого правила не имеет. Из контекста статьи следовало также, что студенты, участвующие в эксперименте, имели предыдущий опыт работы с языком PL/I (Терминалистов) и посему имели привычки ставить точки с запятыми повсюду. Так что результаты этой статьи не дают никаких оснований отдать предпочтение Терминализму в ущерб Сепаратизму.
| Для некоторых других проблем, изучаемых в этой статье, таких пороков не замечено, так что она представляет интерес для людей, интересующихся проектированием языков программирования. |
|
Правило Синтаксиса Точек с Запятой Точки с запятой, как маркеры, ограничивающие инструкции, объявления и утверждения, возможны почти во всех позициях, где они могут появляться. |
p>
| "Почти", поскольку в редких случаях, не встречаемых в этой книге, пропуск точки с запятой может стать причиной синтаксической неоднозначности. |
терминалист: каждую инструкцию, объявление или предложение утверждения заканчивать точкой с запятой;сепаратист: точки с запятой появляются между последовательными элементами, но не после последнего объявления компонента или локального предложения;умеренный Сепаратист: его стиль подобен стилю Сепаратистов, но он не беспокоится о лишних точках с запятой, появляющихся в результате привычки, или в результате перемещения элементов;минималист: вообще не ставит точек с запятой (исключая случаи, когда они требуются по принципу Стиля Точек с Запятой, приводимому ниже).Это одна из тех областей, где предпочтительно позволять каждому пользователю следовать своему собственному стилю, поскольку его выбор не может стать причиной серьезных нарушений. Но при этом внутри одного класса или лучше внутри одной библиотеки классов следует придерживаться единого стиля, соблюдая следующий принцип:
|
Принцип Стиля Точки с Запятой Если вы предпочитаете рассматривать точку с запятой как заключительную часть инструкции, (стиль Терминалиста), поступайте так для всех применимых элементов. Если вы рассматриваете точку с запятой как разделитель, используйте ее только тогда, когда она синтаксически неизбежна или при разделении элементов, появляющихся на одной и той же строке. |
found := found + 1; forthЗдесь точка с запятой должна всегда присутствовать. Ее пропуск будет ошибкой.
В этом обсуждении не дается совет, какой из четырех стилей является предпочтительным. Первое издание этой книги использовало стиль Сепаратистов. Но затем в обсуждениях с коллегами и опытными пользователями я обнаружил (помимо небольшой горстки Терминалистов) почти равное число Сепаратистов и Минималистов. Некоторые из Минималистов были весьма убедительными, в частности, университетский профессор, заявивший, что главная причина, по которой его студенты предпочитают данную нотацию, что в ней не обязательны точки с запятыми, - комментарий, который любой будущий проектировщик языка, при всех его грандиозных планах, должен найти поучительным или, по крайней мере, здравым.
Следует полагаться на свой вкус, пока он согласован и соответствует принципу Стиля Точки с Запятой. (Что же касается этой книги, то вначале скорее по привычке, чем по реальной привязанности я придерживался стиля Сепаратистов, но затем, наслушавшись призывов начать новую жизнь с приходом третьего тысячелетия и порвать со старыми привычками, я удалил все точки с запятыми в течение одной ночи сплошного разгула.)
Выбор правильных имен
Первое, что нуждается в регулировании, - это выбор имен. Имена компонентов следует строго контролировать, что всем принесет пользу.
Высота и ширина
Подобно большинству современных языков, наша нотация не придает особого значения окончаниям строк за исключением строк, завершающихся комментарием. Две или более инструкций (объявления) могут располагаться на одной строке, разделенные в этом случае точками с запятой:
count := count + 1; forthЭтот стиль по ряду причин не очень популярен (многие инструментальные средства для оценки размера ПО используют строки, а не синтаксические единицы); большинство разработчиков предпочитают располагать не более одной инструкции на строку. Действительно, нежелательно упаковывать текст, но в ряде случаев удобно и разумно располагать ряд связанных инструкций на одной строке.
В этой области лучше полагаться на ваши предпочтения и хороший вкус. Если вы применяете внутристрочное группирование, убедитесь, что оно остается умеренным и согласованным с внутренними отношениями между инструкциями. Принцип Точки с Запятой, который появится чуть позже, требует разделения таких инструкций точкой с запятой.
По очевидным причинам объема эта книга широко использует внутристрочное группирование, согласованное со сделанными рекомендациями. Она также избегает расщепления многострочных инструкций на число строк, больше строго необходимого. Нужно лишь помнить, что в независимости от персонального вкуса следует соблюдать гребенчатую структуру.
Заголовочные комментарии и предложения индексации
Хотя формальные элементы класса несут достаточно подробную информацию, следует сопровождать класс неформальными пояснениями. Заголовочные комментарии к подпрограммам и предложения feature, дополненные предложениями indexing, задаваемыми для каждого класса, отвечают этой потребности.
Заголовочные комментарии предложений feature
Как вы помните, класс может иметь несколько предложений feature:
indexing ... class LINKED_LIST [G] inherit ... creation ... feature -- Initialization make is ... feature -- Access item: G is ... ... feature -- Status report before: BOOLEAN is ... ... feature -- Status setting ... feature -- Element change put_left (v: G) is ... ... feature -- Removal remove is ... ... feature {NONE} -- Implementation first_element: LINKABLE [G]. ... endОдна из целей введения нескольких предложений feature состоит в том, чтобы придать разным компонентам различный статус экспорта. Но в данном примере все компоненты за исключением последнего доступны всем клиентам. Другой целью введения нескольких предложений feature, демонстрируемой данным примером, является группировка компонентов по категориям. Комментарий, находящийся на той же строке, что и ключевое слово feature, характеризует категорию. Такие комментарии, подобно заголовочным комментариям подпрограмм, обнаруживаются инструментарием, таким как short, создающим документацию и краткую форму класса.
Восемнадцать категорий с соответствующими комментариями стандартизованы в библиотеках Base, так что каждый компонент (из примерно 2000) принадлежит одной из них. В этом примере показаны некоторые из наиболее важных категорий. Status report соответствует опциям (устанавливаются компоненты в категории Status setting, не включенной в этот пример). Закрытые и выборочно экспортируемые компоненты появляются в категории Implementation. Эти стандартные категории появляются всегда в одном и том же порядке, известном инструментарию (через список, редактируемый пользователем), и будут сохраняться или переустанавливаться при выводе документации. Внутри каждой категории инструментарий перечисляет компоненты в алфавитном порядке для простоты поиска.
Категории покрывают широкий спектр областей применения, хотя для специальных проблемных областей могут понадобиться собственные категории.
Цели анализа
Для понимания задач необходимо разобраться в роли анализа в разработке ПО и определить требования к методу анализа.
Деловой регламент
Мы видели, как инварианты и другие утверждения могут охватить семантические ограничения прикладной области. В терминах анализа это называют деловым регламентом: для класса SCHEDULE можно планировать размещение сегмента только в будущем; в классе SEGMENT определено, что пауза между двумя сегментами не должна превышать установленного значения; в COMMERCIAL рейтинг рекламы должен соответствовать рейтингу передачи.
Принципиальным вкладом ОО-метода является возможность для таких правил использования утверждений и принципов Проектирования по Контракту наряду с заданием структуры.
Практическое предупреждение: даже если реализация не предусматривается, остается риск чрезмерной спецификации. Нужно включать в текст анализа только правила, имеющие высокую степень достоверности и долговечности. Если какое-то правило может меняться, то лучше использовать абстракцию, чтобы оставить место для необходимой адаптации. Например, могут измениться правила совместимости спонсора и рекламодателя, поэтому выбранная абстрактная форма инварианта acceptable_sponsor является приемлемой. Важнейшим преимуществом анализа является возможность выбора, какие особенности принимать во внимание, а какие игнорировать. Здесь действует то же соображение, которое было высказано при обсуждении абстрактных типов данных: нам нужна правда, только правда и ничего кроме правды.
Графики вещания
Сосредоточимся на 24-часовом графике вещания. Его представляет класс (абстракция данных) SCHEDULE. График содержит последовательность отдельных программных сегментов:
class SCHEDULE feature segments: LIST [SEGMENT] endПри проведении анализа необходимо постоянно помнить об опасности избыточной спецификации. Не является ли избыточным использование LIST? Нет: LIST это отложенный класс, описывающий абстрактное понятие последовательности, что соответствует характеру телевизионного вещания - одновременная передача двух сегментов невозможна. Использование LIST фиксирует свойство проблемы, а не ее решение.
Попутно отметим важность повторного использования: применение классов, подобных LIST, сразу открывает доступ к целому набору операций со списками: команде put для добавления элементов, запросу count для получения номера элемента и другим.
Свести понятие графика к списку его сегментов нельзя. Объектная технология, как следует из обсуждения абстрактных типов данных, является неявной; она описывает абстракции путем перечисления их свойств. График передач - это нечто большее, чем список его сегментов, так что необходим отдельный класс. Другие свойства представляются естественным образом:
indexing description: "24-часовой график ТВ вещания" deferred class SCHEDULE feature segments: LIST [SEGMENT] is -- Последовательность сегментов deferred end air_time: DATE is -- Дата вещания deferred end set_air_time (t: DATE) is -- Установка даты вещания require t.in_future deferred ensure air_time = t end print is -- Вывод графика на печать deferred end endОтметим использование отложенной реализации. Это связано с природой анализа, не зависящего от реализации, а часто и от проектирования, так что отложенная форма записи является удобным инструментом. Можно, конечно, вместо отложенной спецификации использовать формализм типа краткой формы. Однако есть два важных довода в пользу полной нотации:
При записи текста в полном соответствии с синтаксисом можно использовать весь набор средств, предоставляемый средой разработки ПО. В частности, механизм компиляции играет в этом случае ту же роль, что и совершенные CASE-средства, осуществляя контроль спецификации на использование типов и других ограничений, позволяя избежать противоречий и двусмысленностей и существенно снизить затраты времени. Средства просмотра и документирования хорошей OO среды столь же полезны для анализа, как и для этапов проектирования и реализации.Использование стандартной нотации существенно облегчает последующий переход к проектированию и реализации программной системы. В этом случае работа сведется к добавлению новых классов, эффективных версий отложенных реализаций и новых компонентов. Такой подход обеспечивает бесшовный процесс разработки, обсуждаемый в следующей лекции.Класс содержит булев запрос in_future для объекта типа DATE, для указания на будущее время выхода в эфир. Следует отметить первое использование предусловия и постусловия для выражения семантических свойств системы в процессе анализа.
Изменчивая природа анализа
В литературе почти не упоминается о том, что наиболее значительный вклад объектной технологии в анализ является не техническим, а организационным. Объектная технология не только обеспечивает новые пути проведения анализа, но и затрагивает природу задачи и ее роль в процессе построения ПО.
Эти изменения следуют из того, что акцент переносится на повторное использование. Вместо того чтобы начинать каждый новый проект на пустом месте, рассматривая требования клиента как Евангелие, учитывается наличие постоянно расширяющегося набора программных компонентов, разработанных во внутренних и внешних проектах. Так что задача сводится не к выполнению спущенного сверху заказа, а к ведению переговоров.
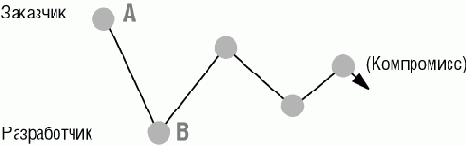
Рис. 9.1. Выработка требований в процессе переговоров
Этот процесс отображен на рис. 9.1. Заказчик начинает с позиции A. Разработчик выступает со своим предложением в B, снимая часть исходных требований или модифицируя их. Его предложения в значительной степени подразумевают повторное использование существующих компонентов, следовательно, снижают затраты средств и времени. Клиенту функциональные потери могут показаться чрезмерными, начинается стадия переговоров, в конечном счете приводящая к приемлемому компромиссу.
Торговля присутствовала всегда. Требования заказчика рассматривались как Евангелие только в некоторых идеализированных описаниях процесса разработки ПО, в учебной литературе и в некоторых правительственных контрактах. В большинстве нормальных ситуаций разработчики обладают возможностью обсуждения требований. Но только с появлением объектной технологии этот неофициальный феномен становится официальной частью процесса разработки ПО, занимая все более важное место по мере развития библиотек повторного использования.
Методы анализа
Далее приведен перечень наиболее известных методов OO анализа приблизительно в хронологическом порядке их опубликования. Несмотря на то, что основное внимание уделяется анализу, большинство методов содержит элементы, относящиеся к разработке и даже реализации. Краткие аннотации не позволяют воздать должное методам и для дальнейшего изучения рекомендуются источники, перечисленные в конце этой лекции.
Метод Coad-Yourdon первоначально был направлен на воплощение идей структурного анализа. Он включает в себя пять этапов: поиск классов и объектов, исходя из предметной области и на основе анализа функций системы, идентификация структур путем поиска отношений "обобщение-специализация" и "общее-частное", определение "субъектов" (групп класс-объект), определение атрибутов; определение сервисов.
Метод OMT (Object Modeling Technique) объединяет концепции объектной технологии и моделирования, основываясь на понятии "сущность-отношение" (entity-relation). Метод включает статическую и динамическую модели. Статическая модель базируется на концепциях класса, атрибута, операции, отношения и агрегирования, динамическая - на основе диаграмм "событие-состояние" позволяет дать абстрактное описание предполагаемого поведения системы.
Метод Shlaer-Mellor изначально ориентирован на создание моделей, допускающих проверку поведения системы, независимо от конкретного проектирования и реализации. Для этого в исходной проблеме выделяются области, задающие различные аспекты: предметная, сервиса (интерфейс пользователя), архитектурная, реализации. Отдельные решения затем связываются воедино для создания завершенной системы.
|
Наличие в Shlaer-Mellor и ряде методов моделирования элементов архитектуры, проектирования и реализации иллюстрирует высказанную ранее мысль о том, что амбиции методов часто выходят за рамки анализа. |
Метод Martin-Odell, известный также как OOIE (Object-Oriented Information Engineering), разделяется на две части. В первой части анализируется объектная структура, идентифицируются типы объектов, их состав, отношения наследования.
Вторая часть анализирует поведение объектов, определяемое динамической моделью, учитывающей состояния объектов и события, которые могут изменить эти состояния.
Метод Booch использует логическую модель (класс и объектная структура) и физическую модель (модуль и архитектура процесса), включая как статические, так и динамические компоненты, в ней применяются многочисленные графические символы. Планируется его включение в язык анализа UML (Unified Modeling Language) (см. ниже).
Метод OOSE (Object-Oriented Software Engineering), также известный как метод Jacobson или как Objectory (название оригинального средства поддержки), основан на использовании сценариев для выявления классов. Рассматривается пять моделей сценариев: доменная модель исходной области приложения и четыре модели этапов разработки - анализа, проектирования, реализации, тестирования.
Метод OSA (for Object-oriented Systems Analysis) предназначен скорее для создания общей модели процесса анализа, а не пошаговой процедуры. Он состоит из трех частей: модели объектных отношений, описывающей объекты, классы и их отношения друг с другом и с "реальным миром", модели объектного поведения, обеспечивающей динамическое представление через состояния, переходы, события, действия и исключения и модели объектного взаимодействия, определяющей возможные взаимодействия между объектами. Метод также поддерживает понятия представления, обобщения и специализации, которые используются для описания взаимодействия и моделей поведения.
Метод Fusion направлен на объединение некоторых из лучших идей более ранних методов. Для анализа он включает объектную модель для данной прикладной задачи и модель интерфейса для описания поведения системы. Модель интерфейса основана на операционной модели, определяющей события и результирующие действия, и модели жизненного цикла, описывающей сценарии эволюции системы. Аналитики должны поддерживать словарь данных для сбора всей информации от различных моделей.
Метод Syntropy определяет три модели.
Наиболее важная модель - "модель реальной или воображаемой ситуации", описывающая элементы ситуации, их структуру и поведение. Модель спецификации - абстрактная модель, рассматривающая систему как механизм реакции на воздействия, располагающий неограниченными аппаратными ресурсами. Модель реализации принимает во внимание реальную вычислительную среду. Предусмотрены различные способы представления каждой модели: описание типов объекта и их статических свойств, диаграммы состояний подобные диаграммам переходов в OMT для описания динамики поведения, диаграммы механизмов для реализации. Метод поддерживает описание одних и тех же объектов с помощью различных интерфейсов, не ограничиваясь простым разделением интерфейса и реализации.
Метод MOSES включает пять моделей: объект-класс, событие для описания сообщений, инициируемых в результате вызова сервисов объекта, "объектные диаграммы" для моделирования динамики изменения состояния, наследование, сервисную структуру для отображения потока данных. Подобно рассматриваемому ниже методу BON, в методе MOSES подчеркивается важность контрактов в определении класса и используются предусловия, постусловия и инварианты в стиле данной книги. Его модель "фонтанирующего процесса" определяет стандартные документы, создаваемые на каждой стадии.
Метод SOMA (Semantic Object Modeling Approach) использует "Объектную Модель Задачи", чтобы сформулировать требования и преобразовать их в "Деловую Объектную Модель". Это одна из немногих попыток извлечения выгоды из формальных подходов, использующая понятие контракта для описания деловых правил, применимых к объектам.
Во время написания книги, разрабатывались два самостоятельных проекта объединения существующих методов. Первый (Brian Henderson-Sellers, Don Firesmith, Ian Graham и Jim Odell) направлен на создание объединенного метода OPEN. Целью второго проекта Rational Corporation является разработка UML (унифицированного языка моделирования), используя в качестве отправной точки методы OMT, Booch и Jacobson.
Нотация BON (Business Object Notation)
Каждый из рассмотренных подходов имеет свои сильные стороны. Метод Business Object Notation (BON), предложенный Nerson и Walden, при минимальной сложности обеспечивает максимальные преимущества и может служить примером комплексного подхода к OO-анализу. Данный краткий обзор основных особенностей метода огранивается обсуждением его вклада в анализ. Для более подробного знакомства можно рекомендовать указанную в библиографии монографию.
На начальном этапе разрабатывался графический формализм представления системных структур. В дальнейшем BON из способа нотации превратился в законченный метод разработки, но оригинальное название было сохранено. BON используется во многих прикладных областях для анализа и разработки систем, в том числе очень сложных.
Метод BON основан на трех принципах: бесшовность, обратимость и контрактность. Бесшовность - непрерывность процесса на протяжении всего жизненного цикла ПО. Обратимость - поддержка прямого и обратного процессов разработки: от анализа к проектированию и реализации и наоборот. Контрактность (вспомните о Проектировании по Контракту) - точное определение семантических свойств каждого программного элемента. BON - практически единственный популярный метод анализа, использующий развитый механизм утверждений, что позволяет аналитикам определить не только структуру системы, но и ее семантику (ограничения, инварианты, свойства ожидаемых результатов).
Ряд других свойств выделяют BON среди OO-методов:
Он обеспечивает "масштабируемость", о которой упоминалось в начале этой лекции. Различные средства и соглашения дают возможность выбрать уровень абстракции системы или описания подсистемы, сосредоточиться на компоненте, скрыть детали. Это выборочное сокрытие предпочтительнее, нежели множественные модели, используемые некоторыми другими методами. Единственность модели обеспечивает бесшовность и обратимость, но в любой момент можно решить, какие аспекты соответствуют текущим потребностям, и скрыть остальное.Метод BON был создан в 1990-е годы.В нем изначально предполагается, что в распоряжении его пользователей будут вычислительные ресурсы, а не только бумага и карандаш или доска. Это позволяет использовать мощные инструментальные средства для отображения комплексной информации. Такие средства описаны в последней лекции этой книги. Для небольших задач вполне достаточно карандаша и бумаги.При всей амбициозности и способности охватить большие и сложные системы метод замечателен своей простотой. Он содержит небольшое количество основных концепций. Необходимо обратить внимание, что изложение формального подхода занимает всего около двух страниц.Поддержка больших систем в BON основана в частности на понятии кластера - группы логически связанных классов. Кластеры могут содержать субкластеры, тем самым формируется вложенная структура и аналитики получают возможность работы на различных уровнях. Некоторые кластеры могут быть библиотеками - серьезное внимание уделяется повторному использованию.
Статическая часть модели сосредоточена на классах и кластерах; динамическая часть описывает объекты, взаимодействия объектов и возможные сценарии упорядочения сообщений.
BON поддерживает несколько вариантов формальных описаний: текстовую нотацию, табличную форму и графические диаграммы.
Текстовая нотация аналогична принятой в этой книге. Поскольку не подразумевается непосредственная компиляция, можно использовать ряд расширений в области утверждений. Например, delta a означает, что компонент может изменить атрибут a, forall и exists применяются для логических формул исчисления предикатов первого порядка, а member_of - для операций с множествами.
Таблица удобна для сжатого описания свойства класса. Общая форма табличного представления класса приведена ниже.
| Short description (Краткое описание) | Indexing information (Индексирующая информация) | ||
| Inherits from (Наследует от) | |||
| Queries (Запросы) | |||
| Commands (Команды) | |||
| Constraints (Ограничения) | |||
Основные соглашения, статические и динамические, приведены на рис. 9.4.
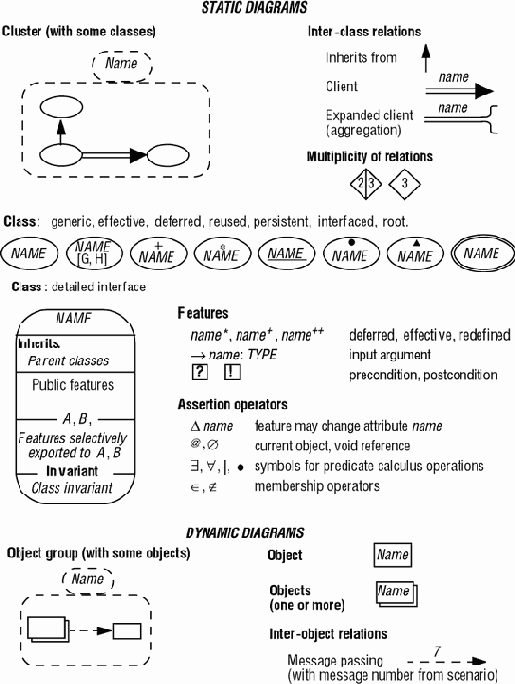
Рис. 9.4. Основные графические обозначения BON ([Walden 1995], приведено с разрешения автора)
Процесс анализа и разработки состоит из семи задач. Порядок их решения соответствует идеальному процессу. В реальной практике его можно изменить и использовать итерации в соответствии с концепцией обратимости. Стандартными являются задачи:
B1 Определение границ системы: что будет включено и не включено в систему, главные подсистемы, пользовательские метафоры, функциональность, библиотеки повторного использования.B2 Составление списка классов-кандидатов, в который вначале включают классы, имеющие отношение к данной области.B3 Выбор классов и формирование кластеров: объединение классов в логические группы, выделение абстрактных, перманентных классов и т. д.B4 Определение классов: развернутое описание классов в терминах запросов, команд и ограничений.B5 Составление эскиза поведения системы: определение схем создания объектов, событий и сценариев.B6 Определение общедоступных компонентов: завершение интерфейсов классов.B7 Совершенствование системы.Метод предписывает в течение процесса разработки следовать терминологии, принятой в данной области. Опыт показывает, что это существенно при разработке любого большого проекта. Это помогает неспециалистам ориентироваться в профессиональном жаргоне, а также позволяет удостовериться, что все специалисты действительно используют одинаковую терминологию (удивительно видеть, как часто это не так!).
Для каждого шага метод определяет точный список того, что необходимо сделать. Он определяет также и отчетные документы. Эта точность определения организационных обязанностей делает BON не только методом анализа и проектирования, но и стратегическим инструментом для руководства проектом.
Облака и провалы
Совместить два последних требования непросто. Конфликт, уже обсуждавшийся в контексте абстрактных типов данных, был настоящим бедствием для всех методов анализа и языков спецификаций. Как однозначно задать определенные свойства, не говоря слишком много? Как обеспечить обозримые, достаточно общие структурные описания без риска неопределенности?
Аналитик идет по горной тропе. Слева скрытая за облаками вершина - туманное царство. Справа подстерегают провалы чрезмерной спецификации, в которые так легко угодить, увлекшись деталями реализации в ущерб общим свойствам системы.
Боязнь риска чрезмерной спецификации характерна для людей, занимающихся анализом. (Говорят, что в этом кругу для уничтожения автора, предлагающего подход X, достаточно сказать "Подход X хорош, но разве он не дитя подхода, ориентированного на реализацию?") По этой причине при проведении анализа часто впадают в другую крайность, полагаясь на описание целостной картины, используя графическую нотацию (часто в виде облаков), неспособную выразить семантические свойства, тогда как для достижения цели A2 требуются точные ответы на конкретные вопросы.
Подобные нотации используются многими традиционными методами анализа. Их успех основан на способности перечисления компонентов системы и графического описания отношений между ними, оставаясь на уровне блок-схем. Для проектов ПО это источник риска, так как при этом слабо отражается семантика. Убежденность, что анализ успешно завершен, в то время как определены лишь основные компоненты и их отношения, не учитывающие глубинные свойства спецификации, может привести к критическим ошибкам.
Далее в данной лекции будут рассмотрены идеи, позволяющие согласовать цели структурного описания и семантической точности.
Оценка
Пример с телевизионной программой находится еще на начальной стадии, но он содержит достаточно для понимания общих принципов подхода. Использованные ОО-концепции и нотация для решения общих задач системного моделирования являются удивительно мощными и интуитивно понятными. А ведь их первоначальное назначение - разработка ПО, и могло казаться, что они непригодны для иных целей. Здесь же метод и нотация в полной мере проявили свои универсальные возможности описания систем различных типов, задавая при этом как общую структуру систем, так и детали семантики.
Рассмотренная выше спецификация не содержит ничего, что связывало бы ее с реализацией или компьютерами. Концепции объектной технологии используются исключительно для описательных целей, компьютеры для этого не нужны.
Естественно, что, если в дальнейшем будет разрабатываться программная система управления работой телестанции, то имеющееся описание обладает неоспоримым преимуществом, поскольку форма его представления в синтаксическом и структурном отношении находится в полном соответствии с описанием ПО. Это основа для бесшовного перехода к проектированию и реализации. В завершенной системе удастся сохранить многие классы, введенные в процессе анализа, снабдив их соответствующей реализацией.
Представление анализа: разные способы
Использование спецификаций, представленных на языке, подобном языку программирования, проиллюстрированное на примере телепрограмм, ставит очевидный вопрос практичности в обычных условиях.
Источником некоторого скептицизма могут быть неудобства восприятия такой нотации для людей, знакомящихся с результатами анализа. Анализ в большей степени, чем любой другой этап разработки, невозможен без сотрудничества с экспертами в данной области, будущими пользователями, менеджерами, руководителями проектов. Можно ли ожидать, что они будут читать спецификацию, которая на первый взгляд напоминает программный текст (хотя это - чистая модель)?
Неожиданно часто ответ - да. Понимание той части нотации, которая служит для анализа, не требует глубоких знаний в программировании, достаточно понимания элементов логики и способа рассуждений, характерных для любой дисциплины. Автор может засвидетельствовать, что успешно использовал такие спецификации с людьми, имеющими различный уровень опыта и образования.
Но это - не конец истории. Приходится сотрудничать с людьми, нерасположенными к формализму. И даже те, кто ценит мощь формализма, нуждаются в других представлениях, в частности, графических. Сражения между графикой и формализмом, формализмом и естественным языком не имеют смысла. На практике для описания нетривиальной системы могут использоваться дополняющие друг друга способы представления:
Формальный текст, как в предыдущем примере.Графическое представление, отображающее системные структуры в виде диаграмм с помощью "пузырьков и стрелок". Графические образы представляют классы, кластеры, объекты и отношения клиентские и наследования.Документ с требованиями на естественном языке.Таблица, например, в представлении метода BON далее в этой лекции.Каждый вариант имеет уникальные преимущества для достижения одних целей анализа и ограничения по отношению к другим целям. В частности:
Документы на естественном языке незаменимы для передачи основных идей и объяснения тонких нюансов.Их недостатком является склонность к неточности и двусмысленности. Таблицы полезны при выделении набора связанных свойств, таких как основные характеристики класса - его родители, компоненты, инварианты.Графические представления превосходны для описания структурных свойства проблемы или системы, показывая компоненты и их отношения. Этим объясняется успех "пузырьков-и-стрелок", продвигаемых "структурным анализом". Их ограниченность проявляется, когда наступает время строгого описания семантических свойств. Например, графическое описание является не лучшим местом для ответа на вопрос, какова максимальная длительность рекламной паузы.Формальные текстовые представления, являются лучшим инструментом для ответов на такие конкретные вопросы, но не могут конкурировать с графикой, когда нужно быстро понять, как организована система.
| Обычный аргумент в пользу графических представлений - шаблонная фраза "изображение стоит тысячи слов". Здесь есть доля правды. Блок-схемы действительно непревзойденно передают впечатление о структуре. Однако это высказывание игнорирует тот факт, что с помощью слов можно передать любые подробности, а неточности рисунка могут приводить к ошибкам. Когда диаграмма предлагается в качестве окончательной спецификации каких-либо тонких особенностей системы, самое время вспомнить загадки типа "найдите все различия" на двух обманчиво похожих рисунках. |
Возникает проблема синхронизации всех представлений. Для этого одно из представлений выбирается в качестве образца (ссылки), а согласованное внесение добавлений и изменений во все остальные представления выполняется специальным программным инструментарием. Лучшим кандидатом на роль образца (фактически единственным) является формальный текст, поскольку только он строго определен и способен охватить и семантику, и структурные свойства.
При таком подходе формальные описания не являются единственным средством анализа. Это дает возможность использовать все разнообразие инструментальных средств, приспособленных к различным уровням квалификации и личным вкусам участников анализа (программисты, менеджеры, конечные пользователи). Поддержка формальных текстов и дополнительных средств анализа может быть встроена в среду программирования. Графическая нотации может использовать CASE-средства, пригодные для создания структурных диаграмм. Тексты на естественном языке могут поддерживаться системой обработки и управления документами. Можно обеспечить аналогичные средства поддержки таблиц. Различные инструментальные средства могут быть как автономными, так и интегрированными в единую среду разработки или анализа.
Изменения в графическом или табличном способе представления должны немедленно отражаться в формальном представлении и наоборот. Например, если на графике класс C показан как потомок класса A (рис. 9.3), то при перемещении указателя на класс B соответствующие средства автоматически внесут необходимые изменения в формальный текст и табличное представление. Наоборот, изменения формального описания сопровождаются модификацией графического и табличного представлений.
Рис. 9.3. Наследственная Связь
Гораздо труднее с помощью инструментальных средств вносить изменения в описание, сделанное на естественном языке. Но если система предусматривает использование структурированных системных описаний с лекциями, разделами и абзацами, то поддержание связей между формальным текстом и документом на естественном языке возможно. Например, можно указать, что некоторый класс или его компонент связан с определенным абзацем требований. Это особенно полезно, когда инструментарий позволяет при внесении любых изменений в исходные требования вывести список всех зависимых элементов формального описания.
Интересно и другое направление - создание из формальных описаний текстов на естественных языках. Идея заключается в восстановлении из формального системного описания обычного текста, выражающего ту же самую информацию в форме, которая не испугает читателей, нерасположенных к формализму.
Не составит труда представить себе инструмент, который на основе нашего эскиза анализа сфабриковал бы следующий текст:
Системные понятия
Основные понятия системы: SCHEDULE, SEGMENT, COMMERCIAL, PROGRAM ... SCHEDULE обсуждается в пункте 2; SEGMENT обсуждается в пункте 3; [и т.д.]Понятие SCHEDULE
......Понятие COMMERCIAL
Общее описание:
Рекламные сегментыВводные замечания.
Понятие COMMERCIAL - это специализированный вариант понятия SEGMENT, и имеет те же свойства и операции, исключения приведены ниже.Переименованные операции.
Свойство sponsor для SEGMENT названо advertizer для COMMERCIAL. ...Переопределенные операции.
...Новые операции.
Следующие операции характеризуют COMMERCIAL: primary, запрос, возвращающий связанное понятие PROGRAM Аргументы: нет [Если нужно, то здесь перечисляются аргументы] Описание: Программа, с которой связана реклама Начальные условия: ... Конечные условия: ... ...Другие операции...Ограничения.
...Изложение смысла инвариантных свойств...Понятие PROGRAM
... и т. д.Все фразы ("Основные понятия системы", "Следующие операции характеризуют..." и т. д.) взяты из стандартного набора предопределенных формулировок, так что это не настоящий "естественный" язык. Тем не менее, может быть создана достаточная иллюзия и достигнут приемлемый для неспециалистов результат. При этом гарантируется совместимость с формальным представлением, так как текст был механически получен именно из него.
Автору неизвестен инструмент, реализующий эту идею, однако цель представляется вполне достижимой. Проект создания такого инструмента гораздо более реалистичен, нежели давно предпринимаемые попытки решения обратной задачи, которые были безуспешными из-за трудностей автоматизированного анализа текстов на естественных языках. Создание текстов более простая задача, точно так же, как реализация синтеза речи гораздо проще ее распознавания.
Такая возможность существует благодаря общности формальной нотации, особенно благодаря наличию поддержки утверждений, что позволяет включить полезные семантические свойства в сгенерированные тексты на естественном языке.Без утверждений мы остались бы в состоянии неопределенности - в облаках.
Программирование телевизионного вещания
Рассмотрим конкретное применение ОО-концепций в интересах чистого моделирования.
В качестве примера рассмотрим организацию планирования сетки телевизионного вещания. Поскольку это знакомая всем прикладная задача, можно начать ее решение без привлечения экспертов и будущих пользователей. Для проведения анализа достаточно полагаться на понимание рядового телезрителя.
Хотя данная попытка является лишь прелюдией к созданию автоматизированной системы управления телевизионным вещанием, в данном случае это несущественно, поскольку нас интересуют исключительно вопросы моделирования.
Программы и реклама
Развивая далее понятие SEGMENT, введем два вида сегментов: программные и коммерческие (рекламные сегменты). Это наводит на мысль использовать наследование.
Рис. 9.2. Программные сегменты и рекламные паузы
Использование наследования в процессе анализа всегда вызывает подозрения. Не следует создавать лишних классов там, где достаточно введения отличительного свойства. Руководящий критерий был дан при рассмотрении наследования: действительно ли каждый предложенный класс реально соответствует отдельной абстракции, характеризующейся специфическими особенностями? В данном случае использование нового класса оправдано, поскольку разумно предложить специальные свойства классу COMMERCIAL, как будет показано ниже. Наследование сопровождается преимуществами открытости: можно позже добавить нового наследника INFOMERCIAL (рекламный ролик) для описания сегмента другого вида.
Начнем работу над COMMERCIAL:
indexing description: "Рекламный сегмент" deferred class COMMERCIAL inherit SEGMENT rename sponsor as advertizer end feature primary: PROGRAM is deferred -- Программа, с которой связан данный сегмент primary_index: INTEGER is deferred -- Индекс сегмента primary set_primary (p: PROGRAM) is -- Связать рекламу с p require program_exists: p /= Void same_schedule: p.schedule = schedule before: p.starting_time <= starting_time deferred ensure index_updated: primary_index = p.index primary_updated: primary = p end invariant meaningful_primary_index: primary_index = primary.index primary_before: primary.starting_time <= starting_time acceptable_sponsor: advertizer.compatible (primary.sponsor) acceptable_rating: rating <= primary.rating endИспользование переименования является еще одним примером полезного средства нотации. Оказывается, оно необходимо не только на этапе реализации, но и для моделирования. Спонсора рекламного фрагмента уместнее называть рекламодателем.
Каждый рекламный сегмент присоединен к некоторому программному (некоммерческому) сегменту, индекс которого в графике задается значением primary_index. Два первых инварианта отражают условия последовательности, последние два - совместимости:
Если программа имеет спонсора, то в течение ее показа приемлема далеко не любая реклама. Никто не будет рекламировать Pepsi-Cola в телешоу, спонсируемом Coca-Cola. Можно выполнить запрос к некоторой базе данных о совместимости.Рейтинг рекламы должен соответствовать программе: реклама бульдозера неуместна в передаче для малышей.Понятие primary требует уточнения. На этом этапе анализа становится ясно, что нужно добавить новый уровень: вместо графика, являющегося последовательностью программных и рекламных сегментов, необходимо рассмотреть последовательность телепрограмм (описывается классом SHOW), каждая из которых имеет собственные компоненты, спонсора и последовательность сегментов. Такое усовершенствование и уточнение, разработанное на основе лучшего понимания проблемы и опыте первых шагов, является нормальным компонентом процесса анализа.
Сегменты
Прежде чем продолжать уточнение и расширение SCHEDULE, необходимо обратиться к понятию SEGMENT. Можно начать со следующего описания:
indexing description: "Отдельные сегменты графика вещания" deferred class SEGMENT feature schedule: SCHEDULE is deferred end -- График, содержащий данный сегмент index: INTEGER is deferred end -- Положение сегмента в графике starting_time, ending_time: INTEGER is deferred end -- Время начала и завершения next: SEGMENT is deferred end -- Следующий сегмент, если он существует sponsor: COMPANY is deferred end -- Основной спонсор rating: INTEGER is deferred end -- Рейтинг сегмента (допустимость просмотра детьми и т.д.) ... Опущены команды change_next, set_sponsor, set_rating и др. ... Minimum_duration: INTEGER is 30 -- Минимальная длительность сегмента в секундах Maximum_interval: INTEGER is 2 -- Максимальная пауза между соседними сегментами в секундах invariant in_list: (1 "= index) and (index "= schedule.segments.count) in_schedule: schedule.segments.item (index) = Current next_in_list: (next /= Void) implies (schedule.segments.item (index + 1) = next) no_next_iff_last: (next = Void) = (index = schedule.segments.count) non_negative_rating: rating >= 0 positive_times: (starting_time > 0) and (ending_time " 0) sufficient_duration: ending_time - starting_time >= Minimum_duration decent_interval: (next.starting_time) - ending_time >= Maximum_interval endКаждый сегмент "может определить" график, частью которого он является, и свое положение с помощью запросов schedule и index. Он содержит запросы starting_time и ending_time, к которым можно добавить и запрос duration, с инвариантом, связывающим длительность сегмента с временем начала и завершения. Такая избыточность допустима в системном анализе, добавление избыточных свойств отражает особенности, представляющие интерес для пользователей или разработчиков. Отношения между избыточными элементами фиксируются в соответствующих инвариантах. Инварианты in_list и in_schedule отражают позицию сегмента в списке сегментов и в графике.
Сегмент также "знает" о следующем сегменте. Инварианты отражают требования последовательности: next_in_list указывает, что если позиция текущего сегмента - i, то следующего - i +1. Инвариант no_next_iff_last служит признаком того, является ли данный сегмент последним в графике.
Два последних инварианта выражают ограничения на продолжительности: sufficient_duration определяет минимальную продолжительность в 30 секунд для фрагмента программы, являющегося сегментом, а decent_interval - максимальную паузу в 2 секунды между двумя последовательными сегментами (темный экран).
Спецификация класса содержит два недостатка, которые почти наверняка придется устранить при следующей итерации. Во-первых, время и продолжительность выражаются целыми числами (в секундах). Целесообразнее применить более абстрактный вариант - использование библиотечных классов DATE, TIME и DURATION. Во-вторых, понятие SEGMENT охватывает два отдельных понятия: фрагмент телевизионной программы и временное планирование. Разграничение этих понятий достигается добавлением в SEGMENT атрибута
content: PROGRAM_FRAGMENTи нового класса PROGRAM_FRAGMENT для описания программного фрагмента вне зависимости от его положения в графике. Компонент duration нужно поместить в PROGRAM_FRAGMENT, а новое инвариантное предложение в SEGMENT примет вид:
content.duration = ending_time - starting_timeДля краткости в остальной части этого эскиза содержание обрабатывается как часть сегмента. Подобные дискуссии типичны для процесса анализа, поддержанного ОО-методом: мы исследуем различные абстракции, обсуждаем, необходимы ли для них различные классы, перемещаем компоненты, если считаем, что они не на своем месте.
Сегмент имеет основного спонсора и рейтинг. Хотя здесь также более выгоден отдельный класс, рейтинг определен как целое число, большее значение рейтинга означает более строгие ограничения. Значение 0 соответствует сегменту, доступному всем зрителям.
Требования
Практические требования к процессу анализа и поддерживающей нотации следуют из приведенного списка целей:
возможность участия в анализе и обсуждении результатов неспециалистов в области ПО (A1, A2);форма представления результатов анализа должна быть непосредственно пригодной для разработчиков ПО (A7);масштабируемость решения (A1);нотация не должна допускать неоднозначного толкования (A3);возможность для читателя быстро получить общее представление об организации системы или подсистемы (A1, A7).Масштабируемость необходима для сложных и (или) больших систем. Метод должен обеспечивать описание высокоуровневой структуры проблемы или системы и выделить в этом описании необходимое число уровней абстракции. Это позволит в любой момент сосредоточиться как на большой, так и на маленькой части системы при сохранении полной картины. Свойства структурирования и абстрагирования объектной технологии будут здесь незаменимыми.
Масштабируемость также означает, что критерии расширяемости и повторного использования, занимающие важное место в предшествующих обсуждениях, в той же мере применимы к анализу, как и к проектированию и реализации ПО. При модификации и создании новых систем можно применять библиотеки элементов спецификаций аналогично использованию библиотек программных компонент при построении реализаций.
Вклад объектной технологии
Объектная технология оказывает влияние и на методы анализа.
Важно то, что основа, заложенная в предшествующих лекциях, содержит более чем достаточно средств, чтобы приступить к моделированию. "Более чем достаточно" означает, что нотация содержит ненужные для анализа элементы:
инструкции (присваивания, циклы, вызовы процедур, ...) и все, что с ними связано;тела подпрограмм в форме do (отложенные подпрограммы deferred нужны для указания операций, реализация которых отсутствует).При игнорировании этих императивных элементов совокупность остальных элементов представляет действенный метод моделирования и нотацию. В частности:
Классы дают возможность организовать описания систем на основе типов объектов в широком понимании слова "объект" (не только физические объекты, но также и важнейшие концепции предметной области).Подход АТД - идея характеризовать объекты с помощью допустимых операций и их свойств - приводит к ясным, абстрактным, эволюционным спецификациям.Отношения между компонентами сводятся к двум основным механизмам - отношениям клиента и наследования. Клиентские отношения, в частности, охватывают такие понятия моделирования, как "быть частью (чего-либо)", агрегирования и соединения.При обсуждении объектов было показано, что различия между ссылочными и развернутыми клиентами соответствуют двум основным видам моделируемых соединений.Наследование - простое, множественное и дублируемое - поддерживает классификацию. Ценность для моделирования представляют даже такие специфические механизмы наследования, как переименование.Утверждения необходимы, чтобы охватить семантику систем, позволяя задавать свойства, отличные от структурных. Проектирование по Контракту мощное руководство по анализу.Библиотеки классов повторного использования, особенно благодаря отложенным классам, обеспечивают готовыми элементами спецификаций.Это вовсе не подразумевает, что ОО-подход обеспечивает все потребности системного анализа (вопрос, который будет обсужден далее), но он представляет реальную основу. Последующий пример послужит доказательством.
и создавая соответствующие документы, мы
Занимаясь анализом и создавая соответствующие документы, мы преследуем семь целей:
|
Цели проведения анализа A1 Понять проблему или проблемы, которые программная (или иная) система должна решить.A2 Задать значимые вопросы о проблеме и о системе.A3 Обеспечить основу для ответов на вопросы о специфических свойствах проблемы и системы.A4 Определить, что система должна делать.A5 Определить, что система не должна делать.A6 Убедиться, что система удовлетворит потребности ее пользователей и определить критерии ее приемки. Это особенно важно, когда система разработана по контракту для внешнего клиента.A7 Обеспечить основу для разработки системы. |
В случае ПО предполагается, что анализ следует за этапом обоснования осуществимости (feasibility study) проекта, на основании которого принято решение о разработке системы. Иногда эти этапы объединены в один, поскольку для определения возможности достижения удовлетворительного результата требуется глубокий анализ. Тогда необходимо добавить пункт A0, обеспечивающий принятие решения о разработке.
Безусловно связанные, перечисленные цели имеют отличия, что побуждает в дальнейшем искать дополняющие друг друга приемы. То, что хорошо для достижения одной цели, может быть неприемлемым для другой.
Цели A2 и A3 наименее полно освещены в литературе и заслуживают особого внимания. Одним из важнейших преимуществ анализа вне зависимости от конечного результата является то, что в процессе его задаются важные вопросы (A2). Какова максимально допустимая температура? Какие категории служащих существуют? В чем разница между облигациями и акциями? Метод анализа позволяет развеять иногда фатальный для разработки туман двусмысленности, предоставляя специалистам данной конкретной области возможность подготовить необходимые исходные данные. Нет ничего хуже, чем обнаружить на завершающем этапе реализации, что маркетинг и технические отделы заказчика имеют противоречивые взгляды на обслуживание оборудования, по умолчанию учитывалась только одна из этих позиций, и никто не догадался уточнить требования заказчика. Именно к пункту A2 постоянно возвращаются в процессе анализа, если возникают тонкие вопросы или противоречивые интерпретации.
